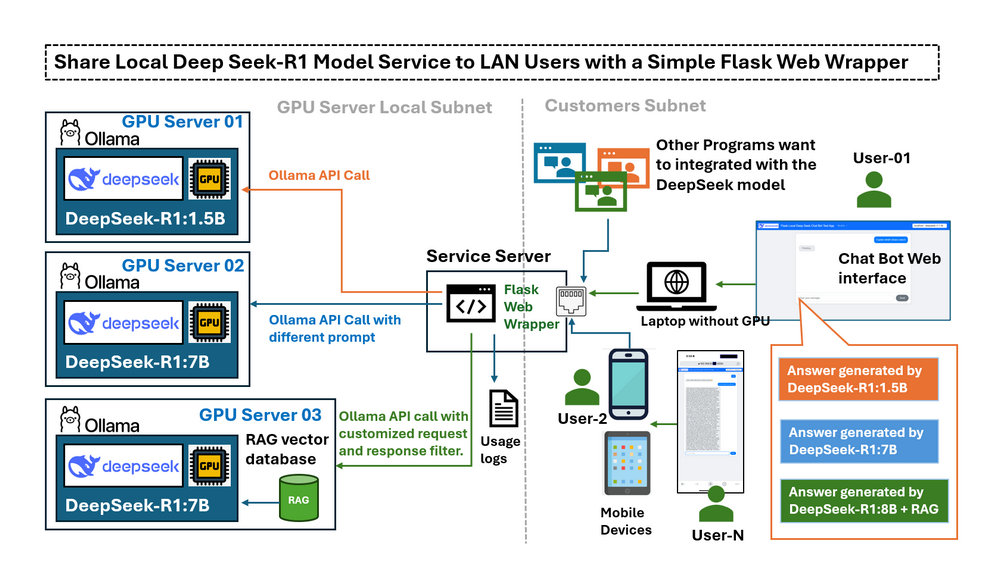
ในบทความก่อนหน้า Deploying DeepSeek-R1 Locally with a Custom RAG Knowledge Data Base เราได้แนะนำขั้นตอนโดยละเอียดเกี่ยวกับการปรับใช้ DeepSeek-R1:7b ในเครื่องด้วยฐานข้อมูลความรู้ RAG ที่กำหนดเองบนเดสก์ท็อปที่มี RTX3060 เมื่อ LLM deepseek-r1:7b ทำงานบนคอมพิวเตอร์ที่ติดตั้ง GPU ในเครื่องแล้ว ความท้าทายใหม่ก็เกิดขึ้น: เราสามารถใช้บริการ LLM บนคอมพิวเตอร์ GPU เท่านั้น จะเกิดอะไรขึ้นถ้าเราต้องการใช้จากอุปกรณ์อื่น ๆ ใน LAN ของฉัน มีวิธีใดบ้างที่ฉันสามารถเข้าถึงได้จากอุปกรณ์มือถือหรือแชร์บริการนี้กับคอมพิวเตอร์เครื่องอื่นในเครือข่ายเดียวกัน โดยค่าเริ่มต้น Ollama จะเปิด API ให้กับ localhost เท่านั้น ซึ่งหมายความว่าอุปกรณ์ภายนอกใน LAN ของคุณไม่สามารถโต้ตอบกับโมเดลได้อย่างง่ายดาย การเปลี่ยนการกำหนดค่าเพื่อเปิดเผย API อย่างเต็มที่อาจแก้ปัญหาการเชื่อมต่อได้ แต่ยังเป็นการลบการป้องกันที่จำกัดการดำเนินการที่อาจมีความเสี่ยง เช่น การสร้างสายสนทนาที่สมบูรณ์ ผู้ใช้ต้องการอินเทอร์เฟซที่ควบคุมได้ซึ่งสามารถ:
-
จำกัดการเข้าถึงเฉพาะฟังก์ชันที่จำเป็น (เช่น การส่งคำถามและการรับคำตอบ)
-
จัดเตรียมอินเทอร์เฟซบนเว็บที่ใช้งานง่ายสำหรับอุปกรณ์มือถือ
-
เปิดใช้งานการเรียก API แบบเป็นโปรแกรมด้วยการควบคุมการเข้าถึง
-
ทำหน้าที่เป็นศูนย์กลางสำหรับการเชื่อมต่อกับเซิร์ฟเวอร์ GPU หลายเครื่องและ LLM เวอร์ชันต่างๆ ของ DeepSeek
# Created: 2025/02/28
# version: v_0.0.1
# Copyright: Copyright (c) 2025 LiuYuancheng
# License: MIT Licenseบทนำ
บทความนี้ให้ภาพรวมของ Flask wrapper สำรวจสถานการณ์การใช้งานจริง และอธิบายวิธีการกำหนดค่า Ollama เพื่อเปิดเผยบริการสำหรับการเรียก LLM API เราจะสำรวจว่าเว็บ wrapper ที่ใช้ Python-Flask อย่างง่ายทำหน้าที่เป็น "สะพาน" ที่ควบคุมระหว่างบริการ LLM ในเครื่อง (deepseek-r1) และผู้ใช้ LAN ได้อย่างไร และตอบสนองความต้องการห้าประการด้านล่าง:
-
เชื่อมต่อเซิร์ฟเวอร์ GPU ในเครื่องหลายเครื่องที่รัน LLM เวอร์ชันต่างๆ ของ DeepSeek ภายใน subnet
-
จำกัดหรือกรองการเข้าถึง Ollama API สำหรับผู้ใช้ LAN
-
เปิดใช้งานการทดสอบจากระยะไกลและการเปรียบเทียบประสิทธิภาพของการตอบสนองของ LLM
-
ให้การเข้าถึงแบบควบคุมไปยังโมเดลเฉพาะทาง/ปรับแต่งอย่างละเอียดโดยไม่ต้องเปิดเผยข้อมูลรับรองของเซิร์ฟเวอร์
-
อำนวยความสะดวกในการออกแบบ prompt โดยการแก้ไขคำถามของผู้ใช้ก่อนส่งโมเดล
ด้วยการใช้เว็บ wrapper นี้ ผู้ใช้จะได้รับการเข้าถึงโมเดล DeepSeek-R1 ที่ปลอดภัยและควบคุมได้ผ่านอินเทอร์เฟซที่ใช้งานง่าย เหมาะสำหรับการโต้ตอบทั้งบนเว็บและแบบเป็นโปรแกรม
บทนำเกี่ยวกับ DeepSeek Flask Web Wrapper
แอปพลิเคชันนี้มีอินเทอร์เฟซที่ใช้งานง่ายสำหรับการเข้าถึงโมเดล LLM หลายรายการจากระยะไกลที่รันบน GPU ต่างๆ (โดยใช้ Ollama เป็นโฮสต์โมเดล) แชทบอทได้รับการออกแบบมาเพื่อวัตถุประสงค์ดังต่อไปนี้:
-
ทดสอบฟังก์ชันการทำงานของอินสแตนซ์ Ollama LLM ที่โฮสต์บน GPU
-
อนุญาตให้เข้าถึง LLM เฉพาะทาง (ฝัง fine-tuned หรือ RAG) ร่วมกันโดยไม่ต้องมีการเข้าถึง SSH โดยตรง
-
เปรียบเทียบประสิทธิภาพของโมเดล LLM ที่แตกต่างกัน เช่น DeepSeek R1-1.5B และ DeepSeek R1-7B ในการตอบสนองต่อคำถามเดียวกัน
ขั้นตอนการทำงานนั้นง่ายมาก:
User → Web Wrapper (Port 5000) → Ollama API (Port 11434, localhost-only/remote) → Response UI เว็บแชทบอทแสดงอยู่ด้านล่าง:
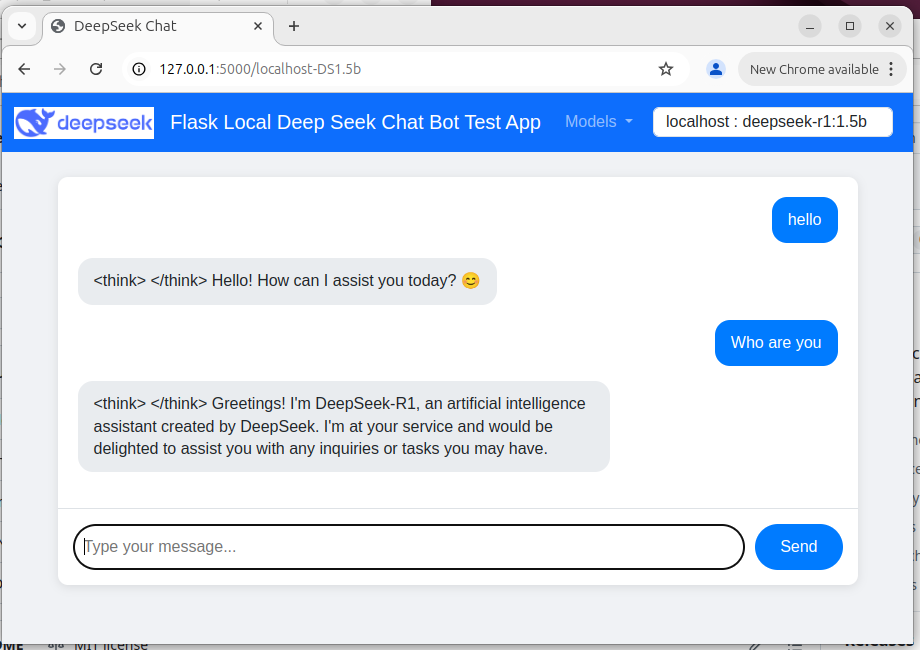
Figure-02: Flask Deepseek service wrapper web chat bot UI , version v_0.0.1 (2025)
ผู้ใช้สามารถโต้ตอบกับแชทบอทผ่าน UI บนเว็บซึ่งมีเมนูแบบเลื่อนลงสำหรับการเลือกโมเดลในแถบนำทาง มุมมองอุปกรณ์มือถือ (โทรศัพท์) แสดงอยู่ด้านล่าง:
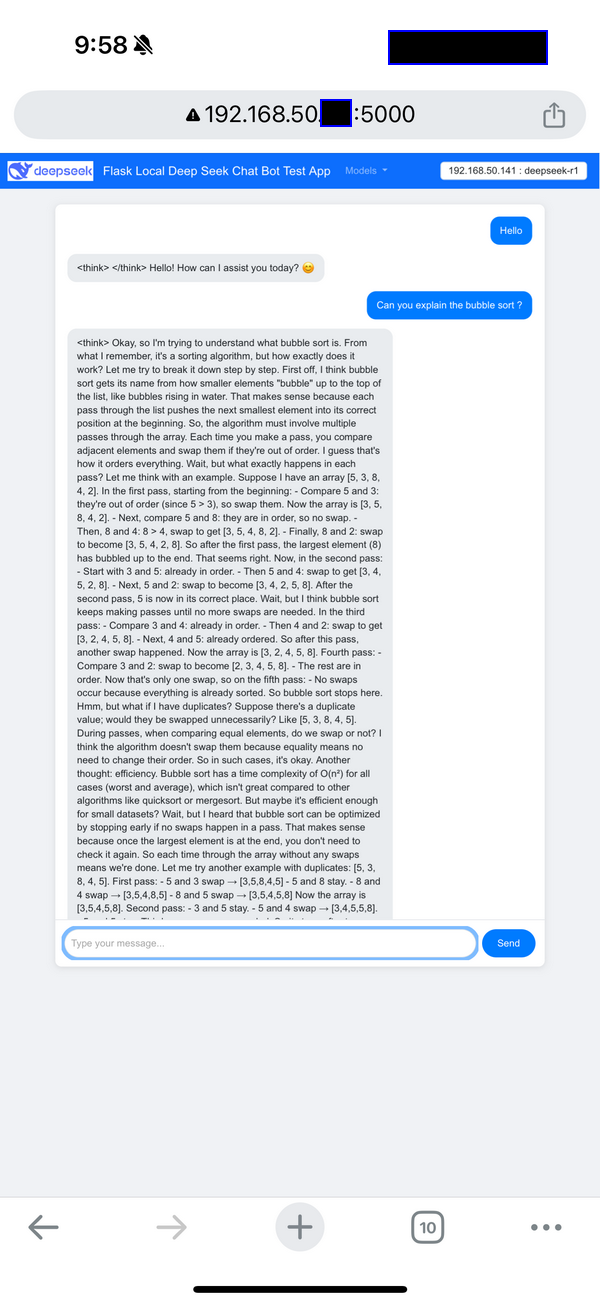
Figure-03: Flask Deepseek service wrapper web chat bot UI on Iphone , version v_0.0.1 (2025)
การเรียกฟังก์ชัน API โปรแกรมระยะไกล (Http GET ) แสดงอยู่ด้านล่าง:
resp = requests.get("http://127.0.0.1:5000/getResp", json={'model':'localhost-DS1.5b', 'message':"who are you"})
print(resp.content)
Program source repo: https://github.com/LiuYuancheng/Deepseek_Local_LATA/tree/main/Testing/1_Simple_Flask_Deepseek_ChatBot
เปิดเผย Ollama Service API ใน LAN
เมื่อใช้เว็บ wrapper คุณสามารถเปิดเผยบริการ Ollama ของคุณให้กับผู้ใช้ LAN ได้อย่างปลอดภัย แทนที่จะแก้ไขการกำหนดค่าของ Ollama โดยตรง ซึ่งจะเปิดเผยฟังก์ชัน API ทั้งหมด wrapper จะทำหน้าที่เป็นตัวกลาง
ตัวอย่างเช่น คำขอ API ทั่วไปผ่าน wrapper อาจมีลักษณะดังนี้:
curl http://localhost:11434/api/generate -d '{ "model": "deepseek-r1:1.5b", "prompt": "Why is the sky blue?"}'
การเข้าถึงที่ควบคุมนี้ทำให้มั่นใจได้ว่าในขณะที่ผู้ใช้สามารถส่งคำถามและรับคำตอบได้ แต่เราไม่มีความสามารถในการแก้ไขสถานะระบบภายในหรือเข้าถึงบันทึกและรายละเอียดการแก้ไขข้อบกพร่อง และหากคุณใช้อุปกรณ์มือถือเช่นโทรศัพท์หรือ Ipad ซึ่งไม่ง่ายต่อการสร้างบรรทัดคำสั่ง การใช้เซิร์ฟเวอร์ Ollama จะไม่สะดวก
ในการกำหนดค่าเซิร์ฟเวอร์ Ollama สำหรับ OS ที่แตกต่างกัน
การตั้งค่าตัวแปรสภาพแวดล้อมบน Mac
หาก Ollama ทำงานเป็นแอปพลิเคชัน macOS ควรตั้งค่าตัวแปรสภาพแวดล้อมโดยใช้ launchctl:
-
สำหรับตัวแปรสภาพแวดล้อมแต่ละตัว ให้เรียก
launchctl setenv
launchctl setenv OLLAMA_HOST "0.0.0.0:11434"
-
รีสตาร์ทแอปพลิเคชัน Ollama
การตั้งค่าตัวแปรสภาพแวดล้อมบน Linux
หาก Ollama ทำงานเป็นบริการ systemd ควรตั้งค่าตัวแปรสภาพแวดล้อมโดยใช้ systemctl:
-
แก้ไขบริการ systemd โดยเรียก
systemctl edit ollama.serviceซึ่งจะเปิดโปรแกรมแก้ไข -
สำหรับตัวแปรสภาพแวดล้อมแต่ละตัว ให้เพิ่มบรรทัด
Environmentภายใต้ส่วน[Service]:[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434" -
บันทึกและออก
-
โหลด
systemdใหม่และรีสตาร์ท Ollama:systemctl daemon-reload
systemctl restart ollama
การตั้งค่าตัวแปรสภาพแวดล้อมบน Windows
บน Windows, Ollama จะสืบทอดตัวแปรสภาพแวดล้อมของผู้ใช้และระบบของคุณ
-
ออกจาก Ollama ก่อนโดยคลิกที่ Ollama ในแถบงาน
-
เริ่มแอปพลิเคชัน Settings (Windows 11) หรือ Control Panel (Windows 10) และค้นหา environment variables
-
คลิกที่ Edit environment variables for your account
-
แก้ไขหรือสร้างตัวแปรใหม่สำหรับบัญชีผู้ใช้ของคุณสำหรับ
OLLAMA_HOSTตั้งค่าเป็น0.0.0.0 -
คลิก OK/Apply เพื่อบันทึก
-
เริ่มแอปพลิเคชัน Ollama จากเมนู Start ของ Windows
Reference : https://github.com/ollama/ollama/blob/main/docs/faq.md#how-do-i-configure-ollama-server
สถานการณ์การใช้งาน
wrapper สามารถนำไปใช้ในสถานการณ์การใช้งาน 4 สถานการณ์ด้านล่างเพื่อแก้ปัญหาของผู้ใช้:
สถานการณ์การใช้งาน 01: การแชร์ที่ปลอดภัยบนเซิร์ฟเวอร์ GPU แบบ Headless
ปัญหา: ลองนึกภาพว่าคุณมีเซิร์ฟเวอร์ GPU ที่รัน DeepSeek บนระบบ Ubuntu ที่ไม่มีสภาพแวดล้อมเดสก์ท็อป คุณต้องการแชร์บริการ LLM กับผู้อื่นใน subnet เดียวกันโดยไม่ต้องเปิดเผยข้อมูลรับรอง SSH หรือฟังก์ชัน Ollama API ทั้งหมด
คุณต้องการจำกัดการเข้าถึง เช่น อนุญาตเฉพาะการตอบสนองโดยไม่แสดงบันทึก "การคิด" ของ deepseek และคุณยังต้องการเพิ่มตัวกรองที่กำหนดเองสำหรับคำขอของผู้ใช้และการตอบสนองของ LLM
โซลูชัน wrapper และแผนภาพขั้นตอนการทำงานแสดงอยู่ด้านล่าง:
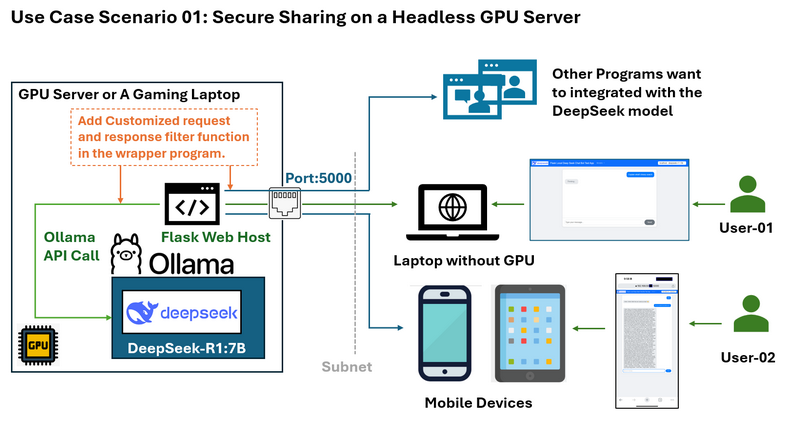
Flask web wrapper ช่วยให้คุณ:
-
เปิดเผยเฉพาะ endpoints API ที่จำเป็น (เช่น การส่งคำถามและการรับคำตอบ) บนพอร์ต 5000
-
ป้องกันการเข้าถึงโดยตรงไปยังส่วนที่ละเอียดอ่อนของ Ollama API
-
จัดเตรียมอินเทอร์เฟซเว็บที่สะอาดซึ่งสามารถเข้าถึงได้จากอุปกรณ์ใดก็ได้บนเครือข่าย รวมถึงอุปกรณ์มือถือ
-
จัดเตรียม http API ที่จำกัดสำหรับโปรแกรมอื่นที่ทำงานบนคอมพิวเตอร์ใน LAN เดียวกัน
สถานการณ์การใช้งาน 02: การจัดการ Query ที่กำหนดเองตามความเชี่ยวชาญของผู้ใช้
ปัญหา: ผู้ใช้ที่แตกต่างกันมีความเชี่ยวชาญในระดับที่แตกต่างกัน ตัวอย่างเช่น ผู้เริ่มต้นอาจต้องการคำอธิบายที่ง่ายขึ้นของอัลกอริทึม เช่น bubble sort ในขณะที่ผู้เชี่ยวชาญอาจต้องการตัวอย่างทางเทคนิคโดยละเอียด
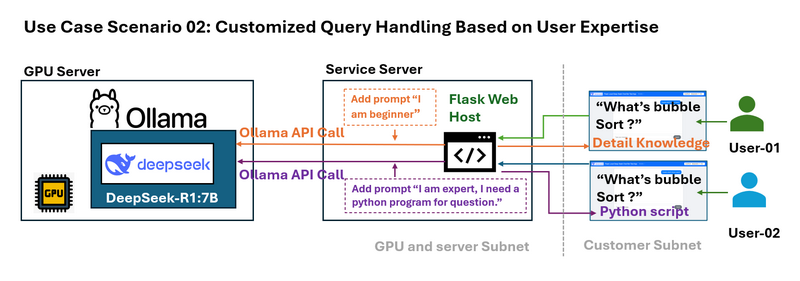
wrapper สามารถสกัดกั้น queries ของผู้ใช้และผนวก prompts เฉพาะบริบทก่อนที่จะส่ง query ไปยัง LLM ตัวอย่างเช่น:
-
Beginner Query: ระบบแก้ไข "What is bubble sort?" เป็น "I am new beginner to sorting algorithms. What is bubble sort?"
-
Advanced Query: ระบบแปลงคำถามเป็น "I am an expert and need a Python example. What is bubble sort?"
การออกแบบ prompt แบบไดนามิกนี้ปรับการตอบสนองให้ตรงกับความต้องการของผู้ใช้
สถานการณ์การใช้งาน 03: การเปรียบเทียบเซิร์ฟเวอร์ Multi-GPU และ Model
ปัญหา: ในสภาพแวดล้อมที่มีเซิร์ฟเวอร์ GPU หลายเครื่องที่รันโมเดล LLM ต่างๆ ของ DeepSeek (เช่น DeepSeek R1-1.5B, DeepSeek R1-7B และ DeepSeek Coder V2) การเปรียบเทียบประสิทธิภาพและการตอบสนองของโมเดลเหล่านี้อาจเป็นเรื่องท้าทายเมื่อจัดการแยกกัน
โซลูชัน wrapper และแผนภาพขั้นตอนการทำงานแสดงอยู่ด้านล่าง:
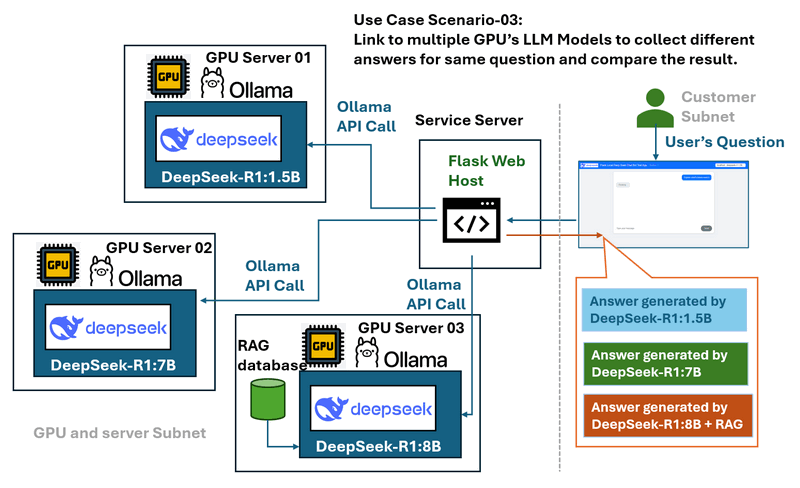
เว็บ wrapper ทำหน้าที่เป็นศูนย์กลางที่:
-
เชื่อมต่อกับเซิร์ฟเวอร์ GPU ในเครื่องหลายเครื่อง
-
จัดเตรียมเมนูแบบเลื่อนลงเพื่อเลือกโมเดลที่แตกต่างกัน
-
อนุญาตให้ผู้ใช้ส่ง query เดียวกันไปยังโมเดลหลายรายการเพื่อการเปรียบเทียบประสิทธิภาพและการตอบสนองที่ง่ายดาย
-
นำเสนออินเทอร์เฟซที่ควบคุมและสอดคล้องกันโดยไม่คำนึงถึงเซิร์ฟเวอร์พื้นฐาน
สถานการณ์การใช้งาน 04: การปรับสมดุลโหลด GPUs และการตรวจสอบ Requests
ปัญหา :
ในคลัสเตอร์ multi-GPU การจัดการ requests จากผู้ใช้หรือที่อยู่ IP ของโหนดที่แตกต่างกันอย่างมีประสิทธิภาพอาจเป็นเรื่องท้าทาย หากไม่มีการกระจาย request ที่เหมาะสม GPU บางตัวอาจโอเวอร์โหลดในขณะที่ GPU อื่นๆ ยังคงไม่ได้ใช้งาน นอกจากนี้ การบันทึกข้อมูล request เพื่อวัตถุประสงค์ในการตรวจสอบและเพิ่มประสิทธิภาพเป็นสิ่งสำคัญ
โซลูชัน wrapper :
เว็บ wrapper ทำหน้าที่เป็นเลเยอร์การจัดการ request โดยใช้ระบบคิวเพื่อบันทึก queries ของผู้ใช้และกระจายอย่างมีประสิทธิภาพไปยังเซิร์ฟเวอร์ GPU ที่พร้อมใช้งาน ด้วยการปรับสมดุล workloads แบบไดนามิก จะป้องกันการโอเวอร์โหลด GPU ตัวเดียวในขณะที่มั่นใจได้ถึงการใช้ทรัพยากรที่เหมาะสมที่สุด บันทึก request ยังสามารถจัดเก็บเพื่อการวิเคราะห์ ทำให้ผู้ดูแลระบบสามารถติดตามรูปแบบการใช้งานและปรับปรุงประสิทธิภาพของระบบ
การปรับใช้โปรแกรมและการใช้งาน
ในการติดตั้ง Ollama และตั้งค่าโมเดล deep seek ในคอมพิวเตอร์ในเครื่อง โปรดทำตาม "Step 1 : Deploy DeepSeek-R1 Model on Your Local Machine" ในคู่มือนี้: https://github.com/LiuYuancheng/Deepseek_Local_LATA/blob/main/Articles/1_LocalDeepSeekWithRAG/readme.md
ในการปรับใช้โปรแกรม โปรดทำตาม setup section ในไฟล์ read me ของ wrapper: https://github.com/LiuYuancheng/Deepseek_Local_LATA/blob/main/Testing/1_Simple_Flask_Deepseek_ChatBot/readme.md
จากนั้นแก้ไข app.py เพื่อเพิ่มรายละเอียดเซิร์ฟเวอร์ GPU (บริการ Ollama) ด้วย ID ที่ไม่ซ้ำกันในโปรแกรม wrapper:
OllamaHosts[] = {'ip': , 'model': }

เรียกใช้คำสั่งต่อไปนี้เพื่อเริ่มแชทบอท:
python app.py
เข้าถึงเว็บ UI ที่ http://127.0.0.1:5000/ หรือ http://:5000/ และเลือกโมเดลที่ต้องการจากเมนูแบบเลื่อนลง

API Request : สำหรับการใช้งานโปรแกรม ให้ใช้ python request lib เพื่อส่ง http GET request เพื่อรับการตอบสนอง:
requests.get("http://127.0.0.1:5000/getResp", json={'model':'localhost-DS1.5b', 'message':"who are you"})
อีกทางเลือกหนึ่ง โปรดดู requestTest.py สำหรับตัวอย่างการใช้งาน API เพิ่มเติม
สรุป
Flask wrapper อย่างง่ายจะปลดล็อกกรณีการใช้งานที่มีประสิทธิภาพสำหรับการปรับใช้ LLM ในเครื่อง:
-
Security: จำกัดการเปิดเผย endpoints ของ Ollama
-
Accessibility: จัดเตรียมอินเทอร์เฟซที่เป็นมิตรกับมือถือ
-
Flexibility: เปิดใช้งานการออกแบบ prompt การทดสอบ multi-model และการปรับสมดุลโหลด
Flask web wrapper อย่างง่ายเป็นโซลูชันที่มีประสิทธิภาพสำหรับการแชร์บริการโมเดล DeepSeek-R1 กับผู้ใช้ LAN อย่างปลอดภัยและมีประสิทธิภาพ ด้วยการเชื่อมช่องว่างระหว่าง Ollama API ในเครื่องและอุปกรณ์ภายนอก wrapper ทำให้มั่นใจได้ว่าบริการยังคงสามารถเข้าถึงได้แต่ยังคงมีการควบคุม ไม่ว่าคุณจะต้องการนำเสนออินเทอร์เฟซมือถือที่คล่องตัว ปกป้อง endpoints API ที่ละเอียดอ่อน หรือเปรียบเทียบโมเดล LLM หลายรายการ แนวทางนี้จะแก้ไขความท้าทายทั่วไปและปรับปรุงความสามารถในการใช้งานของการปรับใช้ DeepSeek ในเครื่อง
อ้างอิง
-
https://github.com/ollama/ollama/blob/main/docs/faq.md#how-do-i-configure-ollama-server
- Project GitHub Repo Link: https://github.com/LiuYuancheng/Deepseek_Local_LATA/tree/main/Testing/1_Simple_Flask_Deepseek_ChatBot
last edit by LiuYuancheng (liu_yuan_cheng@hotmail.com) by 08/02/2025 if you have any problem, please send me a message.
