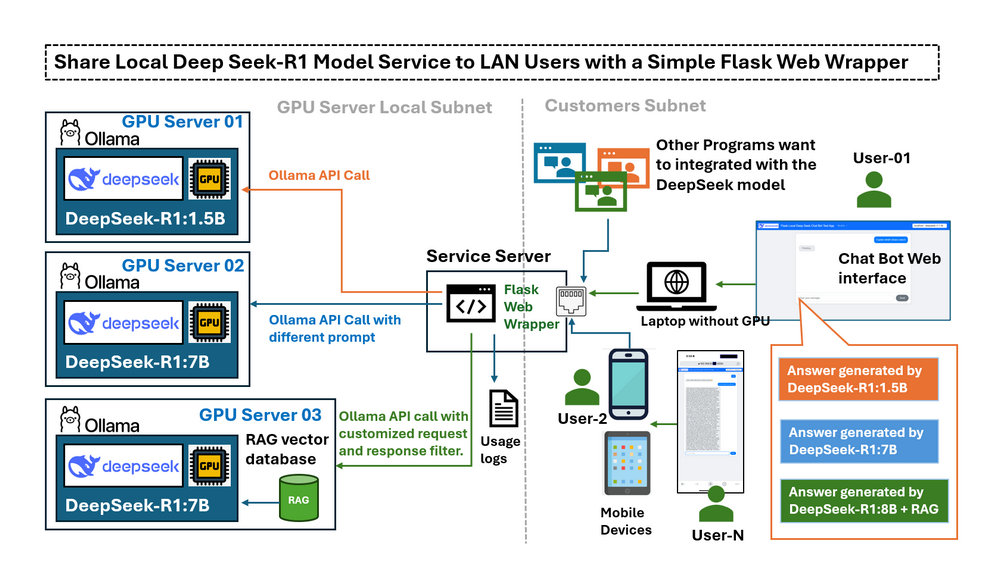
在前一篇文章Deploying DeepSeek-R1 Locally with a Custom RAG Knowledge Data Base中,我們詳細介紹了如何在配備 RTX3060 的桌上型電腦上,使用客製化的 RAG 知識庫在本機部署 DeepSeek-R1:7b 的步驟。一旦 LLM deepseek-r1:7b 在本機配備 GPU 的電腦上運行,就會出現一個新的挑戰:我們只能在 GPU 電腦上使用 LLM 服務,如果我們想從 LAN 中的其他裝置使用它該怎麼辦?有沒有辦法可以從行動裝置存取它,或與同一網路中的其他電腦分享此服務?預設情況下,Ollama 只會將其 API 開放給 localhost,這表示 LAN 中的外部裝置無法輕易地與模型互動。變更組態以完全公開 API 可能可以解決連線問題,但同時也會移除限制潛在風險操作(例如建立完整的對話鏈)的保護措施。使用者需要一個受控的介面,可以:
-
限制僅存取必要的功能(例如,傳送問題和接收回應)。
-
為行動裝置提供直觀的網頁介面。
-
啟用具有受控存取的程式化 API 呼叫。
-
作為連接到多個 GPU 伺服器和不同 DeepSeek LLM 版本的中央樞紐。
# Created: 2025/02/28
# version: v_0.0.1
# Copyright: Copyright (c) 2025 LiuYuancheng
# License: MIT License簡介
本文概述了 Flask 封裝器,探討了實際的使用案例情境,並說明如何設定 Ollama 以公開 LLM API 呼叫的服務。我們將探討一個簡單的基於 Python-Flask 的 Web 封裝器如何作為本機 LLM 服務 (deepseek-r1) 和 LAN 使用者之間的受控「橋樑」,並滿足以下五個請求:
-
連接子網路中運行不同 DeepSeek LLM 版本的多個本機 GPU 伺服器。
-
限制或過濾 LAN 使用者的 Ollama API 存取。
-
啟用 LLM 回應的遠端測試和效能比較。
-
提供對特殊/微調模型的受控存取,而無需公開伺服器憑證。
-
透過在提交模型之前修改使用者查詢來促進提示工程。
透過實作此 Web 封裝器,使用者可以透過使用者友好的介面安全地、受控地存取 DeepSeek-R1 模型,該介面適用於基於 Web 的互動和程式化互動。
DeepSeek Flask Web 封裝器簡介
此應用程式提供了一個使用者友好的介面,用於遠端存取在不同 GPU 上運行的多個 LLM 模型(使用 Ollama 託管模型)。聊天機器人旨在用於以下目的:
-
測試 GPU 託管的 Ollama LLM 實例的功能。
-
允許共享存取專門的 LLM(微調或 RAG 嵌入),而無需直接 SSH 存取。
-
比較不同 LLM 模型(例如 DeepSeek R1-1.5B 和 DeepSeek R1-7B)對相同查詢的回應效能。
工作流程非常簡單:
User → Web Wrapper (Port 5000) → Ollama API (Port 11434, localhost-only/remote) → Response 聊天機器人 Web UI 如下所示:
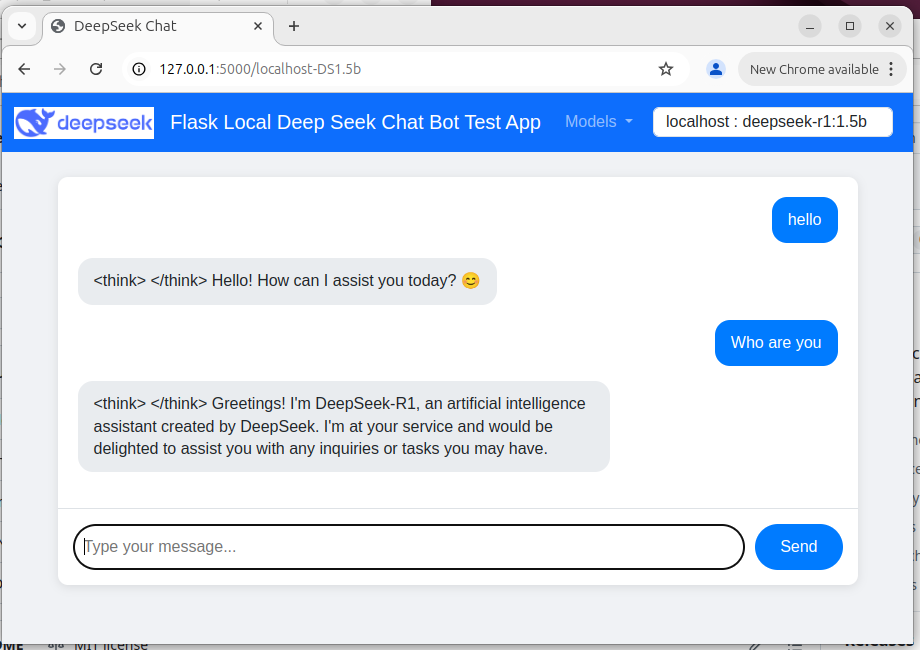
Figure-02: Flask Deepseek service wrapper web chat bot UI , version v_0.0.1 (2025)
使用者可以透過基於 Web 的 UI 與聊天機器人互動,該 UI 在導覽列中包含一個模型選擇下拉式選單。行動裝置(手機)視圖如下所示:
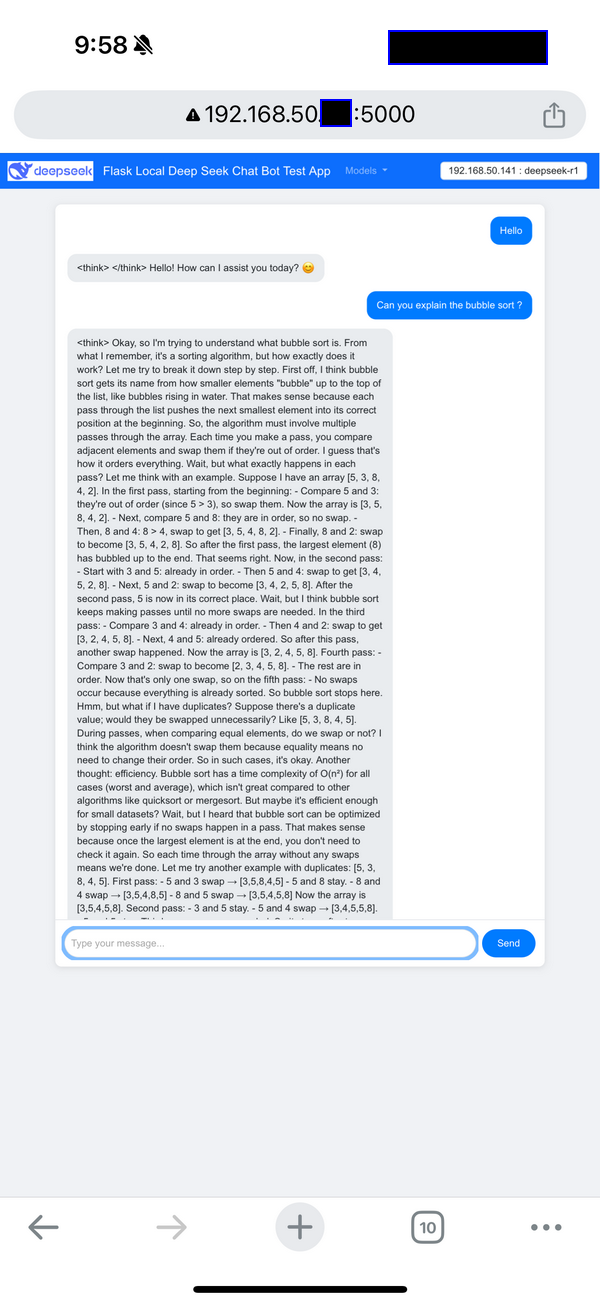
Figure-03: Flask Deepseek service wrapper web chat bot UI on Iphone , version v_0.0.1 (2025)
遠端程式 API 函數呼叫 (Http GET ) 如下所示:
resp = requests.get("http://127.0.0.1:5000/getResp", json={'model':'localhost-DS1.5b', 'message':"who are you"})
print(resp.content)
Program source repo: https://github.com/LiuYuancheng/Deepseek_Local_LATA/tree/main/Testing/1_Simple_Flask_Deepseek_ChatBot
在 LAN 中公開 Ollama 服務 API
使用 Web 封裝器,您可以安全地將 Ollama 服務公開給 LAN 使用者。封裝器充當中間人,而不是直接修改 Ollama 的組態(這會公開所有 API 函數)。
例如,透過封裝器的典型 API 請求可能如下所示:
curl http://localhost:11434/api/generate -d '{ "model": "deepseek-r1:1.5b", "prompt": "Why is the sky blue?"}'
這種受控存取可確保使用者可以傳送問題並接收答案,但我們無法修改內部系統狀態或存取日誌和偵錯詳細資訊,如果您使用手機或 Ipad 等行動裝置,這些裝置不容易建立命令列,則使用 Ollama 伺服器會很不方便。
若要為不同的作業系統設定 Ollama 伺服器,
在 Mac 上設定環境變數
如果 Ollama 作為 macOS 應用程式運行,則應使用 launchctl 設定環境變數:
-
對於每個環境變數,呼叫
launchctl setenv。
launchctl setenv OLLAMA_HOST "0.0.0.0:11434"
-
重新啟動 Ollama 應用程式。
在 Linux 上設定環境變數
如果 Ollama 作為 systemd 服務運行,則應使用 systemctl 設定環境變數:
-
透過呼叫
systemctl edit ollama.service來編輯 systemd 服務。這將開啟一個編輯器。 -
對於每個環境變數,在
[Service]區段下新增一行Environment:[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434" -
儲存並退出。
-
重新載入
systemd並重新啟動 Ollama:systemctl daemon-reload
systemctl restart ollama
在 Windows 上設定環境變數
在 Windows 上,Ollama 會繼承您的使用者和系統環境變數。
-
首先,透過在工作列中點擊 Ollama 來退出 Ollama。
-
啟動設定 (Windows 11) 或控制台 (Windows 10) 應用程式,並搜尋環境變數。
-
點擊編輯您帳戶的環境變數。
-
為您的使用者帳戶編輯或建立一個新的
OLLAMA_HOST變數,將其值設定為0.0.0.0 -
點擊確定/套用以儲存。
-
從 Windows 開始功能表啟動 Ollama 應用程式。
Reference : https://github.com/ollama/ollama/blob/main/docs/faq.md#how-do-i-configure-ollama-server
使用案例情境
封裝器可以應用於以下 4 個使用案例情境,以解決使用者的問題:
使用案例情境 01:在無頭 GPU 伺服器上安全共享
問題: 假設您有一個在沒有桌面環境的 Ubuntu 系統上運行 DeepSeek 的 GPU 伺服器。您想要與同一子網路上的其他人共享 LLM 服務,而無需公開 SSH 憑證或完整的 Ollama API 功能。
您想要限制存取,例如僅允許回應而不顯示 deepseek 的「思考」日誌,並且您還想要為使用者的請求和 LLM 的回應新增一些自訂過濾器。
封裝器解決方案和工作流程圖如下所示:
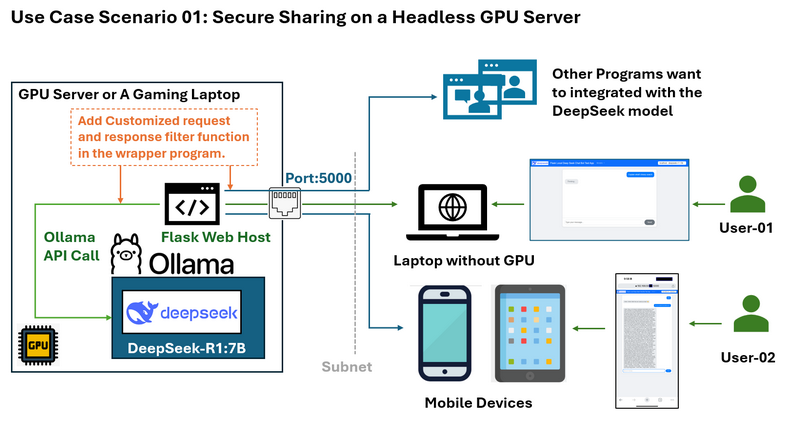
Flask Web 封裝器允許您:
-
僅公開必要的 API 端點(例如,傳送問題和接收答案)在 5000 埠上。
-
防止直接存取 Ollama API 的敏感部分。
-
提供可從網路上任何裝置(包括行動裝置)存取的簡潔 Web 介面。
-
為在同一 LAN 中的電腦上運行的其他程式提供有限的 http API。
使用案例情境 02:基於使用者專業知識的自訂查詢處理
問題: 不同的使用者具有不同的專業知識水準。例如,初學者可能需要對氣泡排序等演算法的簡化說明,而專家可能需要詳細的技術範例。
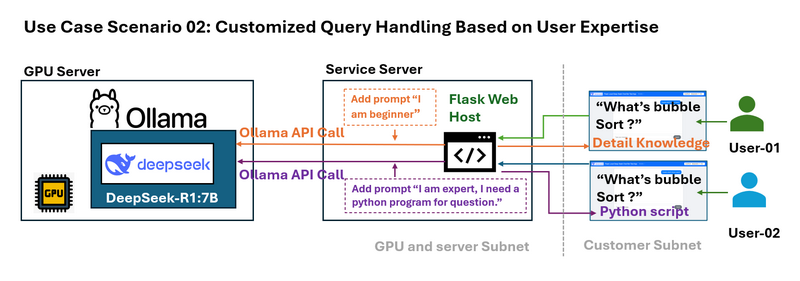
封裝器可以攔截使用者查詢,並在將查詢傳送到 LLM 之前附加特定於上下文的提示。例如:
-
初學者查詢: 系統將「什麼是氣泡排序?」修改為「我是排序演算法的新手。什麼是氣泡排序?」
-
進階查詢: 它將問題轉換為「我是專家,需要一個 Python 範例。什麼是氣泡排序?」
這種動態提示工程可以根據使用者的需求量身定制回應。
使用案例情境 03:多 GPU 伺服器和模型比較
問題: 在具有多個運行各種 DeepSeek LLM 模型(例如 DeepSeek R1-1.5B、DeepSeek R1-7B 和 DeepSeek Coder V2)的 GPU 伺服器的環境中,單獨管理時,比較這些模型的效能和回應可能具有挑戰性。
封裝器解決方案和工作流程圖如下所示:
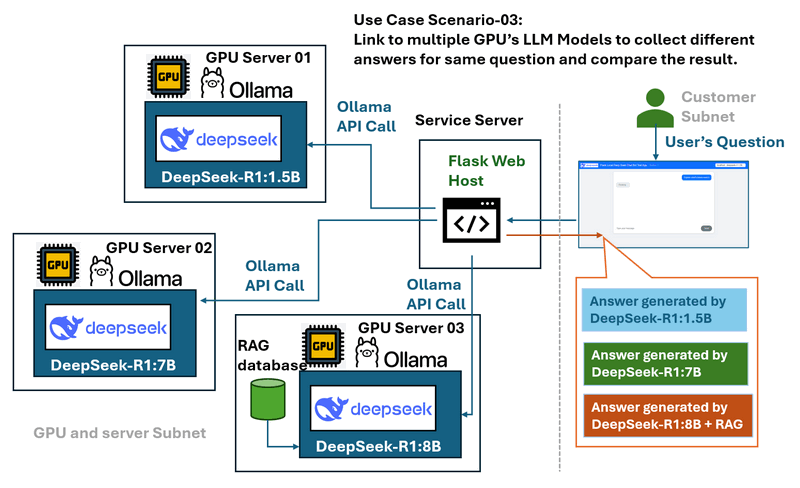
Web 封裝器充當中央樞紐,可以:
-
連接到多個本機 GPU 伺服器。
-
提供一個下拉式選單來選擇不同的模型。
-
允許使用者將相同的查詢傳送到多個模型,以便輕鬆比較效能和回應。
-
提供一個受控且一致的介面,而不管底層伺服器如何。
使用案例情境 04:GPU 負載平衡和請求監控
問題:
在多 GPU 叢集中,有效管理來自不同使用者或節點 IP 位址的請求可能具有挑戰性。如果沒有適當的請求分配,某些 GPU 可能會過載,而其他 GPU 則未充分利用。此外,記錄請求資料以進行監控和最佳化至關重要。
封裝器解決方案:
Web 封裝器充當請求管理層,實作一個佇列系統來記錄使用者查詢,並將它們有效地分配到可用的 GPU 伺服器上。透過動態平衡工作負載,它可以防止單個 GPU 過載,同時確保最佳的資源利用率。還可以儲存請求日誌以進行分析,使管理員能夠追蹤使用模式並提高系統效能。
程式部署和使用
若要在本機電腦上安裝 Ollama 並設定 deep seek 模型,請按照本手冊中的「步驟 1:在本機電腦上部署 DeepSeek-R1 模型」進行操作:https://github.com/LiuYuancheng/Deepseek_Local_LATA/blob/main/Articles/1_LocalDeepSeekWithRAG/readme.md
若要部署程式,請按照封裝器讀我檔案中的設定區段進行操作:https://github.com/LiuYuancheng/Deepseek_Local_LATA/blob/main/Testing/1_Simple_Flask_Deepseek_ChatBot/readme.md
然後修改 app.py 以在封裝器程式中新增具有唯一 ID 的 GPU 伺服器 (Ollama 服務) 詳細資訊:
OllamaHosts[] = {'ip': , 'model': }

執行以下命令以啟動聊天機器人:
python app.py
在 http://127.0.0.1:5000/ 或 http://:5000/ 存取 Web UI,並從下拉式選單中選擇所需的模型。

API 請求:對於程式使用,請使用 python request lib 發送 http GET 請求以取得回應:
requests.get("http://127.0.0.1:5000/getResp", json={'model':'localhost-DS1.5b', 'message':"who are you"})
或者,請參閱 requestTest.py 以取得更多 API 使用範例。
結論
一個簡單的 Flask 封裝器解鎖了本機 LLM 部署的強大使用案例:
-
安全性:限制 Ollama 端點的公開。
-
可存取性:提供行動裝置友好的介面。
-
靈活性:啟用提示工程、多模型測試和負載平衡。
簡單的 Flask Web 封裝器是一個強大的解決方案,可以安全有效地與 LAN 使用者共享 DeepSeek-R1 模型服務。透過彌合本機 Ollama API 和外部裝置之間的差距,封裝器可確保服務保持可存取但受控。無論您是希望提供簡化的行動介面、保護敏感的 API 端點,還是比較多個 LLM 模型,此方法都可以解決常見的挑戰並增強本機 DeepSeek 部署的可用性。
參考文獻
-
https://github.com/ollama/ollama/blob/main/docs/faq.md#how-do-i-configure-ollama-server
- Project GitHub Repo Link: https://github.com/LiuYuancheng/Deepseek_Local_LATA/tree/main/Testing/1_Simple_Flask_Deepseek_ChatBot
last edit by LiuYuancheng (liu_yuan_cheng@hotmail.com) by 08/02/2025 if you have any problem, please send me a message.
