Over the past year, large language models (LLMs) have been booming and developing vigorously. As an enthusiast of data systems, it would indeed seem outdated not to pursue and research this hot field at all. This article summarizes my recent practical experiences attempting to write an LLM application using Rust with flows.network.
Concepts Related to Large Language Models
When talking about large language models, it's impossible not to mention ChatGPT and OpenAI. Although OpenAI recently changed its CEO, there's no denying the significant role it has played in the development and promotion of LLMs. From the perspective of individual developers and small companies, training and deploying large language models on their own is practically unrealistic. As a data systems developer enthusiast, I prefer to illustrate the concept of LLMs using the following diagram.
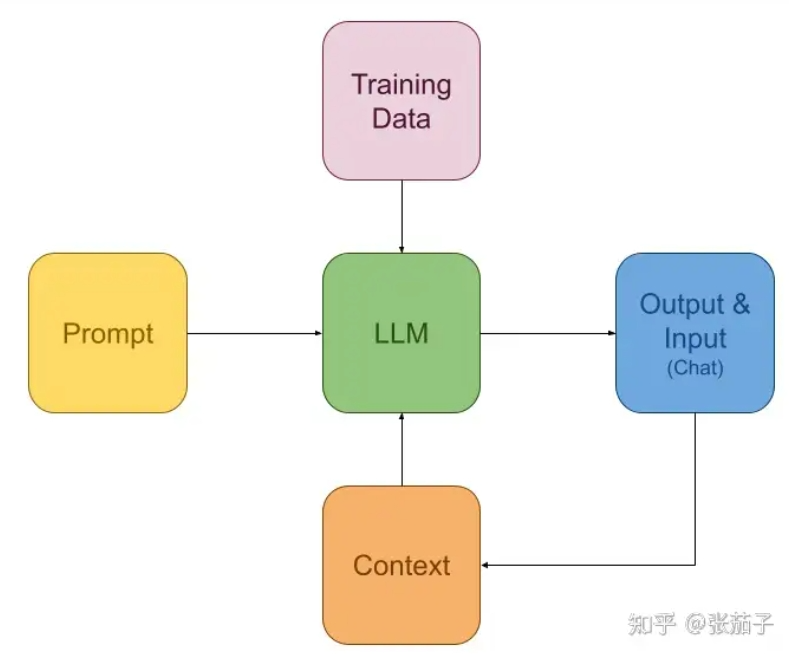
From the perspective of application developers, an LLM can be viewed as a function composed and trained from a vast amount of data. Since this function is static, prompts and contextual information (context) are needed as inputs during usage. The function's purpose is to generate output that most likely satisfies the user's needs based on the prompt and context. This output, along with the user's input (chat), is then fed back into the LLM as context.
Using this mindset, developers of large language models do not need to overly concern themselves with the internal details of the LLM; they only need to prepare suitable input for this "function" in an appropriate manner. Of course, there are nuances involved in optimizing prompts, but it must be said that today's large language models are already quite "intelligent." Often, a simple prompt can achieve very good results.
(Note: The diagram mentioned in the original text was not provided, but the explanation given illustrates how LLMs operate based on prompts and context.)
RAG and Vector Store
When discussing the applications of Large Language Models (LLMs), it's essential to mention RAG (Retrieval-Augmented Generation) and Vector Stores. RAG is an acronym that emerged alongside the rise of LLMs. Its primary purpose is to address the challenge that typical LLMs cannot easily incorporate new knowledge rapidly. For instance, ChatGPT has been limited to responding with information up to 2021. While this limitation can be addressed through fine-tuning, the process itself is costly and time-consuming.
In the early stages, information retrieval within RAG frameworks was often implemented using Vector Stores. This is because LLMs are predominantly applied in question-and-answer systems. For such systems, user inputs are typically natural language queries, and traditional keyword-based search systems often fail to return satisfactory results. Therefore, Vector Stores combined with some form of language model are used to compute embeddings (vector representations). These embeddings are then used by the Vector Store to retrieve relevant information, which is provided to the LLM as context. The traditional RAG process using Vector Stores can be illustrated as follows:
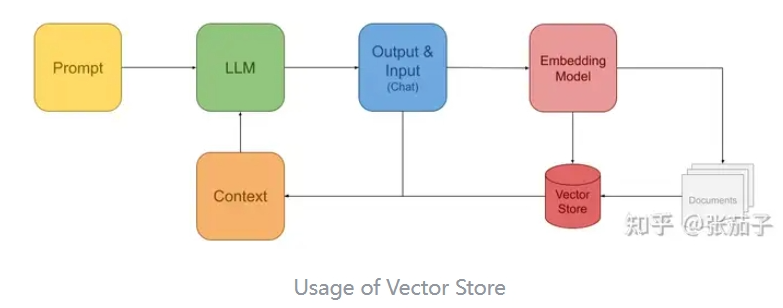
Within this framework, an Embedding Model can convert both user queries and existing documents into vectors within the same metric space. This conversion ensures that the vector generated from the user's query is similar to the vectors derived from relevant document content. Consequently, when invoking the LLM, the retrieved information can be supplied to the LLM as context, enabling it to respond to various pieces of information contained within the document repository and to answer questions pertaining to newly added documents.
In this model, the Embedding Model and the LLM do not necessarily need to be the same model. The role of the Embedding Model is primarily to generate similar vectors and does not require strong reasoning capabilities. The effectiveness of this framework can sometimes be constrained by the performance of the Embedding Model.
By leveraging Vector Stores and embedding models, RAG systems enhance the capability of LLMs to provide contextually relevant responses, even when dealing with new or updated information. This approach effectively bridges the gap between static LLM knowledge and dynamic real-world data.
RAG and the Assistant Model
However, there is a more powerful RAG framework that has begun to see widespread adoption recently. This framework is based on the so-called "Assistant" model. An "Assistant" acts as a third-party agent between the LLM and the user. This role operates similarly to a bot in a conversation, capable of executing commands output by the LLM, performing queries, and returning the results to the LLM as context. This model can be illustrated as follows:
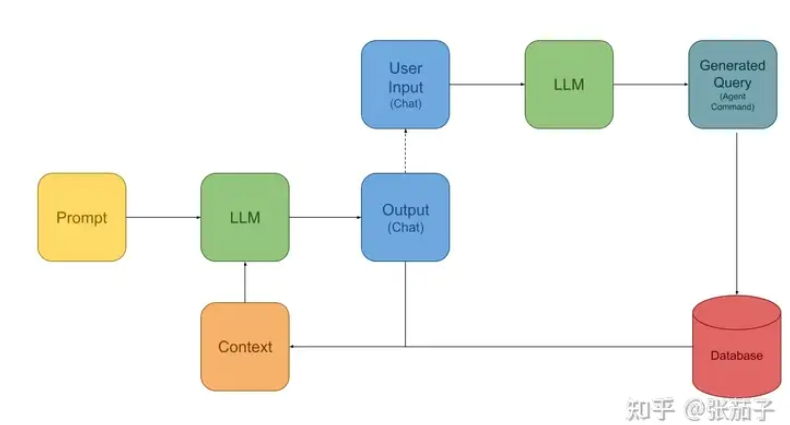
This model is based on a simple yet effective idea: the LLM is powerful enough to transform user questions—or "translate" them—into formatted statements, such as SQL queries or function calls described in JSON. Through prompt engineering, the LLM can be prompted to output commands it believes will fetch the required data. An Agent then executes these queries and returns the results to the current session's context, allowing the LLM to obtain the latest information it needs. This model is highly flexible, enabling queries to traditional databases without pre-processing using an embedding model. Additionally, the LLM can perform multiple rounds of queries based on its understanding before delivering the final results, making it a very powerful framework.
Furthermore, the Assistant framework can be utilized to control external systems, not just for querying data. This effectively maximizes the potential applications of LLMs.
Development of LLM Applications
As an ordinary developer, we may not be able to influence the large-scale frameworks or developments surrounding LLMs, but we can certainly leverage existing tools to build useful applications. Among the hottest frameworks for LLM applications currently, LangChain stands out. Such tools are essentially workflow management systems that provide callable functions and methods to organize workflows, allowing users to weave their application logic together.
Out of interest, I chose flows.network to develop a Telegram GPT application. Flows.Network is a workflow realization for large language models implemented in Rust. It provides numerous callable methods and tools to help describe your LLM application flow. The application you write gets compiled into WebAssembly format and runs on the hosting platform provided by Flows.Network. Currently, this hosting service is free.

The diagram above showcases the integrations already provided by Flows.Network. These integrations are implemented as APIs and come with Rust SDKs for calling them. Users only need to focus on organizing the logic of their application and calling these methods. Another reason for choosing Flows.Network over LangChain is its lightweight framework, which doesn't introduce the heavy abstractions that LangChain has been criticized for.
I used Flows.Network to create a Telegram Bot that can assist with Q&A and learning Japanese. You can find the entire source code [here] (note: the link should be replaced with the actual URL if you're referring to a specific repository). This Bot implements convenient commands and supports maintaining conversation context via Reply-To messages.
It's worth noting that due to the peculiar support for Markdown syntax in Telegram, to ensure that the Markdown text output by ChatGPT can be correctly processed, I even wrote a simple Parser using Nom to handle and escape the Markdown syntax in the text. The specific code can be found in the src/markdown.rs file.
Currently, the Flows.Network code needs to be built in WebAssembly mode and is not convenient for local execution and debugging. This is one of its major issues. Fortunately, once properly configured, pushing to your GitHub repository automatically triggers the build and deployment, making the writing experience relatively convenient. Hopefully, this aspect can be improved in the future.
Summary
This article introduced the general concepts of LLM applications and shared the experience of writing an LLM application using Flows.Network. Overall, I personally really enjoy being able to write LLM applications in Rust. Flows provides the necessary APIs so that I don't have to deal with various interfaces myself. Deploying with Wasm for Function-as-a-Service (FaaS) is also a very convenient experience. Hopefully, more platforms like this will emerge and make the development of various GPT applications easier.
The use of Rust in developing LLM applications, coupled with the streamlined deployment process using WebAssembly, represents a promising direction for developers looking to leverage the power of LLMs efficiently and securely. While there are still challenges, such as the lack of ease in local testing and debugging, the convenience of automatic builds and deployments makes the overall development experience quite positive. It's anticipated that improvements will continue to be made, enhancing the developer experience further.
At the same time, you are welcome to fork and try out the Telegram Bot I wrote: https://github.com/shanzi/Telegram-ChatGPT
Translated from: https://zhuanlan.zhihu.com/p/667494969
