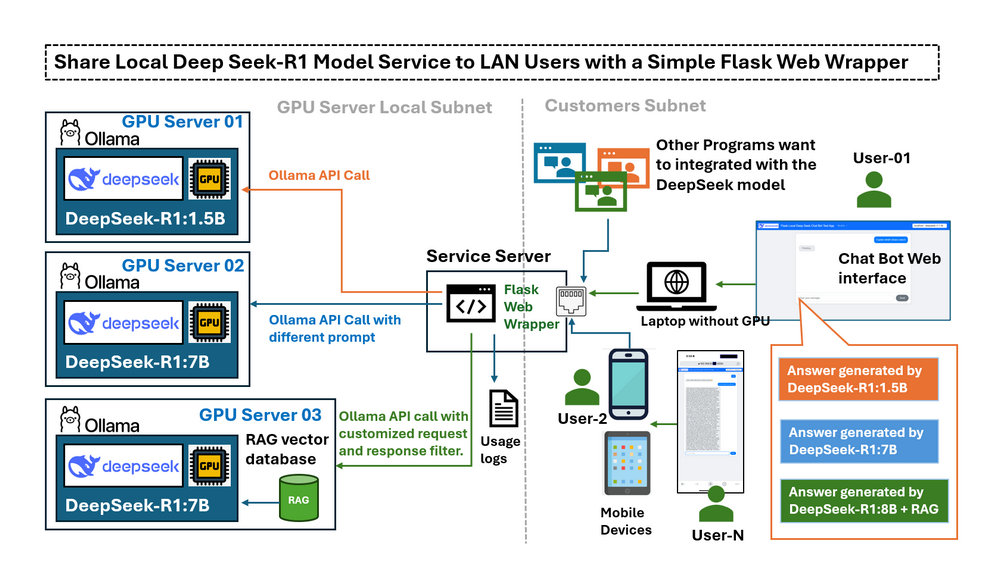
在前一篇文章Deploying DeepSeek-R1 Locally with a Custom RAG Knowledge Data Base中,我们详细介绍了如何在配备RTX3060的台式机上,使用定制的RAG知识数据库在本地部署DeepSeek-R1:7b的步骤。一旦LLM deepseek-r1:7b在本地配备GPU的计算机上运行,一个新的挑战就出现了:我们只能在GPU计算机上使用LLM服务,如果我想从局域网中的其他设备使用它该怎么办?是否可以从移动设备访问它,或者与同一网络中的其他计算机共享此服务?默认情况下,Ollama仅将其API开放给localhost,这意味着局域网中的外部设备无法轻松地与模型交互。更改配置以完全公开API可能会解决连接问题,但同时也消除了限制潜在风险操作(例如创建完整的对话链)的保护措施。用户需要一个受控的界面,该界面可以:
-
限制仅访问必要的功能(例如,发送问题和接收响应)。
-
为移动设备提供直观的基于Web的界面。
-
支持通过受控访问进行编程API调用。
-
充当连接到多个GPU服务器和不同DeepSeek LLM版本的中央枢纽。
# Created: 2025/02/28
# version: v_0.0.1
# Copyright: Copyright (c) 2025 LiuYuancheng
# License: MIT License介绍
本文概述了 Flask 包装器,探讨了实际用例场景,并解释了如何配置Ollama以公开LLM API调用的服务。我们将探讨一个简单的基于Python-Flask的Web包装器如何充当本地LLM服务(deepseek-r1)和LAN用户之间的受控“桥梁”,并满足以下五个请求:
-
连接子网内运行不同DeepSeek LLM版本的多个本地GPU服务器。
-
限制或过滤LAN用户的Ollama API访问。
-
启用LLM响应的远程测试和性能比较。
-
提供对专用/微调模型的受控访问,而无需暴露服务器凭据。
-
通过在模型提交之前修改用户查询来促进提示工程。
通过实现此Web包装器,用户可以通过用户友好的界面安全,受控地访问DeepSeek-R1模型,该界面适用于基于Web的交互和编程交互。
DeepSeek Flask Web 包装器简介
此应用程序为远程访问在不同GPU上运行的多个LLM模型(使用Ollama托管模型)提供了一个用户友好的界面。该聊天机器人旨在用于以下目的:
-
测试GPU托管的Ollama LLM实例的功能。
-
允许共享访问专用LLM(微调或RAG嵌入),而无需直接SSH访问。
-
比较不同LLM模型(例如DeepSeek R1-1.5B和DeepSeek R1-7B)对同一查询的响应的性能。
工作流程非常简单:
User → Web Wrapper (Port 5000) → Ollama API (Port 11434, localhost-only/remote) → Response 聊天机器人Web UI如下所示:
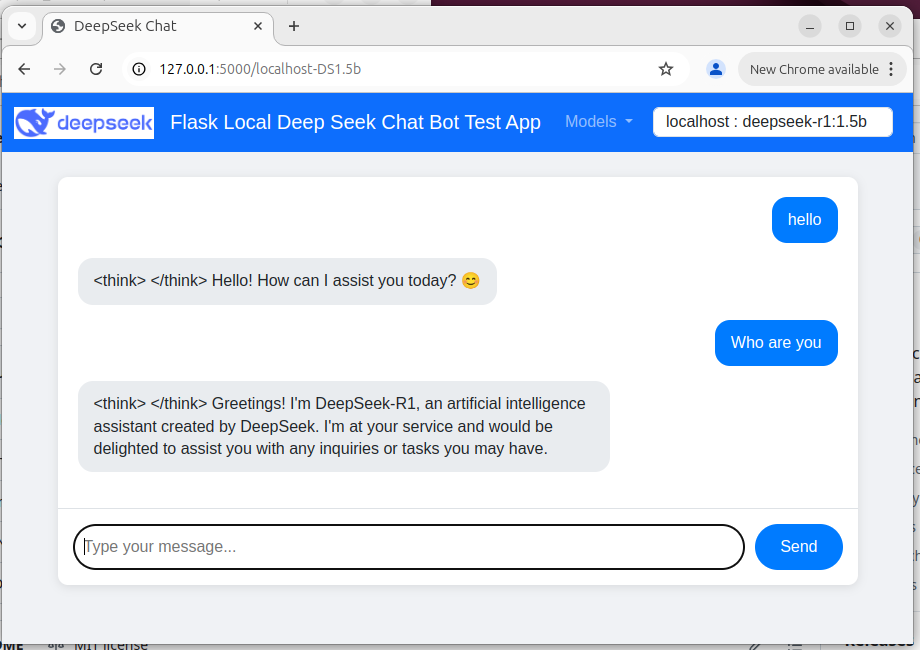
Figure-02: Flask Deepseek service wrapper web chat bot UI , version v_0.0.1 (2025)
用户可以通过基于Web的UI与聊天机器人进行交互,该UI在导航栏中包含一个模型选择下拉列表。移动设备(手机)视图如下所示:
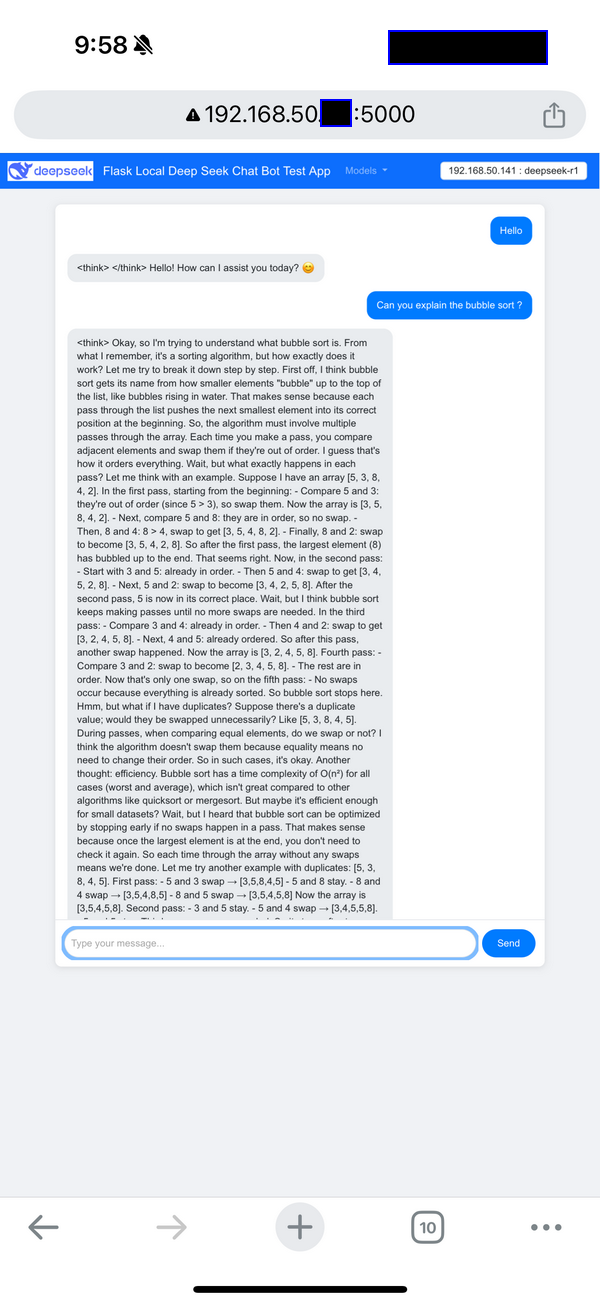
Figure-03: Flask Deepseek service wrapper web chat bot UI on Iphone , version v_0.0.1 (2025)
远程程序API函数调用(Http GET)如下所示:
resp = requests.get("http://127.0.0.1:5000/getResp", json={'model':'localhost-DS1.5b', 'message':"who are you"})
print(resp.content)
Program source repo: https://github.com/LiuYuancheng/Deepseek_Local_LATA/tree/main/Testing/1_Simple_Flask_Deepseek_ChatBot
在LAN中公开Ollama服务API
使用Web包装器,您可以安全地将Ollama服务公开给LAN用户。包装器充当中间人,而不是直接修改Ollama的配置(这将公开所有API函数)。
例如,通过包装器的典型API请求可能如下所示:
curl http://localhost:11434/api/generate -d '{ "model": "deepseek-r1:1.5b", "prompt": "Why is the sky blue?"}'
这种受控的访问确保了用户可以发送问题并接收答案,但是我们没有能力修改内部系统状态或访问日志和调试详细信息,并且如果您使用手机或Ipad等移动设备,这些设备不容易创建命令行,则使用Ollama服务器将很不方便。
要为不同的OS配置Ollama服务器,
在Mac上设置环境变量
如果Ollama作为macOS应用程序运行,则应使用launchctl设置环境变量:
-
对于每个环境变量,调用
launchctl setenv。
launchctl setenv OLLAMA_HOST "0.0.0.0:11434"
-
重新启动Ollama应用程序。
在Linux上设置环境变量
如果Ollama作为systemd服务运行,则应使用systemctl设置环境变量:
-
通过调用
systemctl edit ollama.service来编辑systemd服务。这将打开一个编辑器。 -
对于每个环境变量,在
[Service]部分下添加一行Environment:[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434" -
保存并退出。
-
重新加载
systemd并重新启动Ollama:systemctl daemon-reload
systemctl restart ollama
在Windows上设置环境变量
在Windows上,Ollama继承您的用户和系统环境变量。
-
首先,通过单击任务栏中的Ollama来退出Ollama。
-
启动“设置”(Windows 11)或“控制面板”(Windows 10)应用程序,然后搜索环境变量。
-
单击编辑帐户的环境变量。
-
为您的用户帐户编辑或创建一个新的
OLLAMA_HOST变量,将其值设置为0.0.0.0 -
单击“确定/应用”以保存。
-
从Windows“开始”菜单启动Ollama应用程序。
Reference : https://github.com/ollama/ollama/blob/main/docs/faq.md#how-do-i-configure-ollama-server
用例场景
包装器可以应用于以下4个用例场景,以解决用户的问题:
用例场景01:在无头GPU服务器上安全共享
问题:假设您有一个在没有桌面环境的Ubuntu系统上运行DeepSeek的GPU服务器。您想与同一子网上的其他人共享LLM服务,而无需暴露SSH凭据或完整的Ollama API功能。
您想限制访问,例如仅允许响应而不显示deepseek的“思考”日志,并且您还想为用户的请求和LLM的响应添加一些自定义过滤器。
包装器解决方案和工作流程图如下所示:
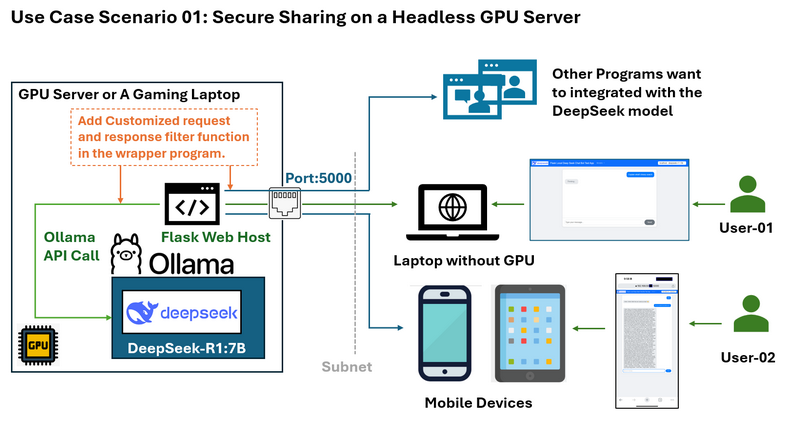
Flask Web包装器允许您:
-
仅在端口5000上公开必要的API端点(例如,发送问题和接收答案)。
-
防止直接访问Ollama API的敏感部分。
-
提供可从网络上任何设备(包括移动设备)访问的干净Web界面。
-
为同一LAN中计算机上运行的其他程序提供有限的http API。
用例场景02:基于用户专业知识的自定义查询处理
问题:不同的用户具有不同的专业知识水平。例如,初学者可能需要对冒泡排序之类的算法进行简化的解释,而专家可能需要详细的技术示例。
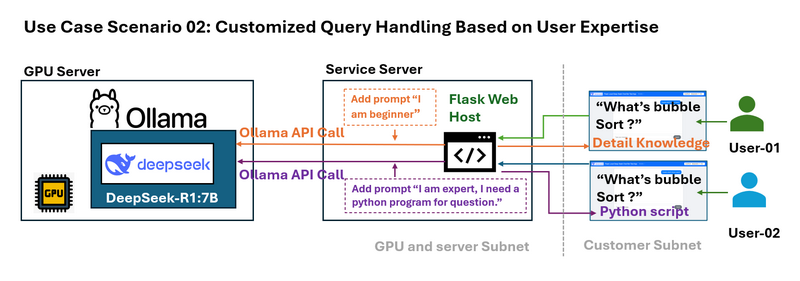
包装器可以拦截用户查询,并在将查询发送到LLM之前附加特定于上下文的提示。例如:
-
初学者查询:系统将“什么是冒泡排序?”修改为“我是排序算法的新手。什么是冒泡排序?”
-
高级查询:它将问题转换为“我是一位专家,需要一个Python示例。什么是冒泡排序?”
这种动态提示工程可以根据用户的需求定制响应。
用例场景03:多GPU服务器和模型比较
问题:在具有多个运行各种DeepSeek LLM模型(例如DeepSeek R1-1.5B,DeepSeek R1-7B和DeepSeek Coder V2)的GPU服务器的环境中,当单独管理这些模型时,比较这些模型的性能和响应可能具有挑战性。
包装器解决方案和工作流程图如下所示:
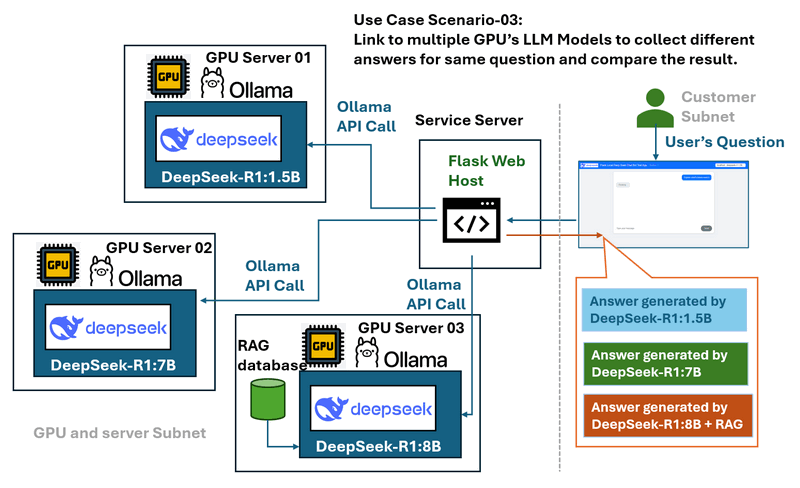
Web包装器充当中央枢纽,可以:
-
连接到多个本地GPU服务器。
-
提供一个下拉菜单来选择不同的模型。
-
允许用户将相同的查询发送到多个模型,以便轻松进行性能和响应比较。
-
提供受控且一致的界面,而与底层服务器无关。
用例场景04:GPU负载平衡和请求监控
问题:
在多GPU集群中,有效地管理来自不同用户或节点IP地址的请求可能具有挑战性。如果没有适当的请求分配,某些GPU可能会过载,而其他GPU仍未得到充分利用。此外,记录请求数据以进行监视和优化至关重要。
包装器解决方案:
Web包装器充当请求管理层,实现队列系统以记录用户查询并将其有效地分配到可用的GPU服务器上。通过动态平衡工作负载,它可以防止单个GPU过载,同时确保最佳的资源利用率。还可以存储请求日志以进行分析,从而使管理员可以跟踪使用模式并提高系统性能。
程序部署和使用
要在本地计算机中安装Ollama并设置deep seek模型,请按照本手册中的“步骤1:在本地计算机上部署DeepSeek-R1模型”进行操作:https://github.com/LiuYuancheng/Deepseek_Local_LATA/blob/main/Articles/1_LocalDeepSeekWithRAG/readme.md
要部署该程序,请按照包装器自述文件中的设置部分进行操作:https://github.com/LiuYuancheng/Deepseek_Local_LATA/blob/main/Testing/1_Simple_Flask_Deepseek_ChatBot/readme.md
然后修改app.py以在包装器程序中添加具有唯一ID的GPU服务器(Ollama服务)详细信息:
OllamaHosts[] = {'ip': , 'model': }

执行以下命令以启动聊天机器人:
python app.py
在http://127.0.0.1:5000/或http://:5000/访问Web UI,然后从下拉菜单中选择所需的模型。

API请求:对于程序使用,请使用python request lib发送http GET请求以获取响应:
requests.get("http://127.0.0.1:5000/getResp", json={'model':'localhost-DS1.5b', 'message':"who are you"})
或者,请参阅requestTest.py以获取更多API使用示例。
结论
一个简单的Flask包装器为本地LLM部署解锁了强大的用例:
-
安全性:限制Ollama端点的暴露。
-
可访问性:提供移动友好的界面。
-
灵活性:启用提示工程,多模型测试和负载平衡。
简单的Flask Web包装器是与LAN用户安全有效地共享DeepSeek-R1模型服务的强大解决方案。通过弥合本地Ollama API和外部设备之间的差距,该包装器可确保服务保持可访问但受控。无论您是希望提供简化的移动界面,保护敏感的API端点还是比较多个LLM模型,此方法都可以解决常见的挑战并增强本地DeepSeek部署的可用性。
参考
-
https://github.com/ollama/ollama/blob/main/docs/faq.md#how-do-i-configure-ollama-server
- Project GitHub Repo Link: https://github.com/LiuYuancheng/Deepseek_Local_LATA/tree/main/Testing/1_Simple_Flask_Deepseek_ChatBot
last edit by LiuYuancheng (liu_yuan_cheng@hotmail.com) by 08/02/2025 if you have any problem, please send me a message.
