背景:AI编程中上下文的重要性
如果像Claude 3.5 Sonnet这样的大型模型的“智能”是推动AI编程能力逐步跃升的关键因素,那么另一个关键因素就是上下文长度。
目前,Claude 3.5 Sonnet提供的最大上下文长度为200k个token。虽然这对于对话模型来说已经绰绰有余——可以轻松处理50,000甚至100,000字的书籍——但对于涉及数十或数百个代码文件(每个文件包含数百或数千行代码)的编程项目来说,仍然远远不够。此外,大型模型根据输入和输出token的数量收费,边际成本不容忽视。
这两个特点促使Cursor和Windsurf等AI编程工具实施了许多优化,目标如下:
- 准确提取与任务相关的代码以节省上下文长度,从而实现多步骤任务优化并提供更好的用户体验。
- 最大限度地减少阅读“不必要”的代码内容,不仅是为了改进任务优化,也是为了降低成本。
在上述约束和目标下,Cursor和Windsurf采用了不同的优化策略来增强其产品体验。然而,这种“优化”往往涉及权衡,只能产生局部最优解,不可避免地会牺牲用户体验的某些方面。
本文的目的是帮助你和我都了解它们“优化”背后的方法和逻辑。通过掌握这些调整中涉及的权衡,我们可以更好地利用不同产品的优势和劣势。这种理解将使我们能够在各种场景中切换工具并调整使用方法,最终为我们的任务找到最佳解决方案。
结论:Windsurf用于入门,Cursor用于优化
根据最近的经验以及对12月15日Cursor 0.43.6和Windsurf 1.0.7的实际评估,得出以下结论:
1. 对于执行基本任务的初学者:Windsurf > Cursor Agent > Cursor Composer(普通模式)
在Agent模式下,执行基本任务的性能超过标准Cursor Composer模式。这是因为Agent模式会解释任务,扫描代码库,定位文件,读取代码,并逐步执行操作以完成任务。
与Cursor Composer模式下的Agent相比,Windsurf的Agent显示出更好的任务理解和多步骤执行能力。
2. Agent模式的关键限制:文件读取不完整
此限制会影响复杂的项目和大型代码文件。
- 在Cursor的Agent模式下,默认情况下是读取文件的头250行。如果需要更多内容,它偶尔会自动再扩展250行。对于某些明确定义的任务,Cursor会执行搜索,每次搜索最多返回100行代码。
- Windsurf默认情况下每文件读取200行,如有必要,最多重试3次,总共最多读取600行。
3. 对于单文件操作,Cursor优于Windsurf
在Cursor中,如果你@一个特定文件,它将尝试尽可能完整地读取该文件(测试最多2000行)。
在Windsurf中,@一个文件仅仅帮助它找到相关文件,但不会提示完整读取该文件。这是两种工具之间逻辑上的一个关键区别。
4. 当你理解项目结构时:Cursor在单文件关注方面表现更好
如果你知道自己在做什么,并且你的任务与特定文件有关,那么在Cursor中使用@来关注单个文件会产生更好的结果。相反,使用@codebase并不能保证Cursor会将所有相关代码包含在上下文中。相反,它使用较小的模型来分析和总结每个文件,导致必要的代码覆盖不完整。
3. 测试过程
以上所有结论都基于我每天大量使用Cursor和Windsurf(500多个小时)以及有针对性的测试。在这个测试中,我使用了一个包含1955行的视频字幕文件。字幕文件包含时间戳和松散耦合的内容,因此很容易确定AI编程工具是否真正读取了文件以及读取了多少内容——没有留下任何“猜测”的空间。
为了确保工具是真正“读取”而不是通过检索增强生成(RAG)进行总结,我在每500行随机插入不相关的内容。这些随机插入的内容包括:
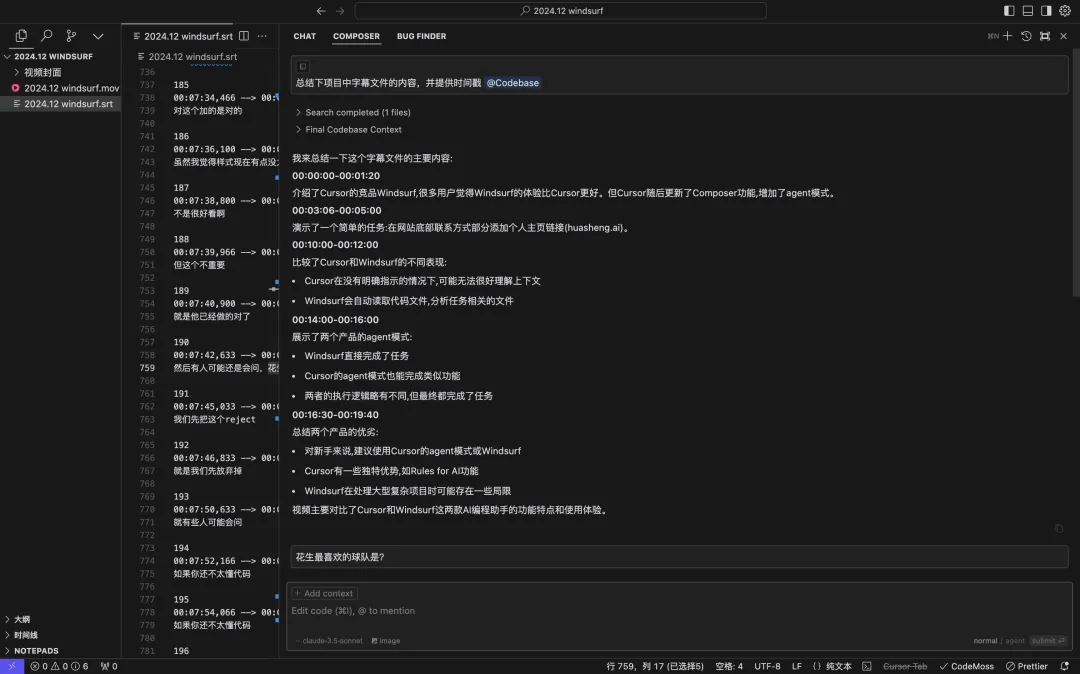
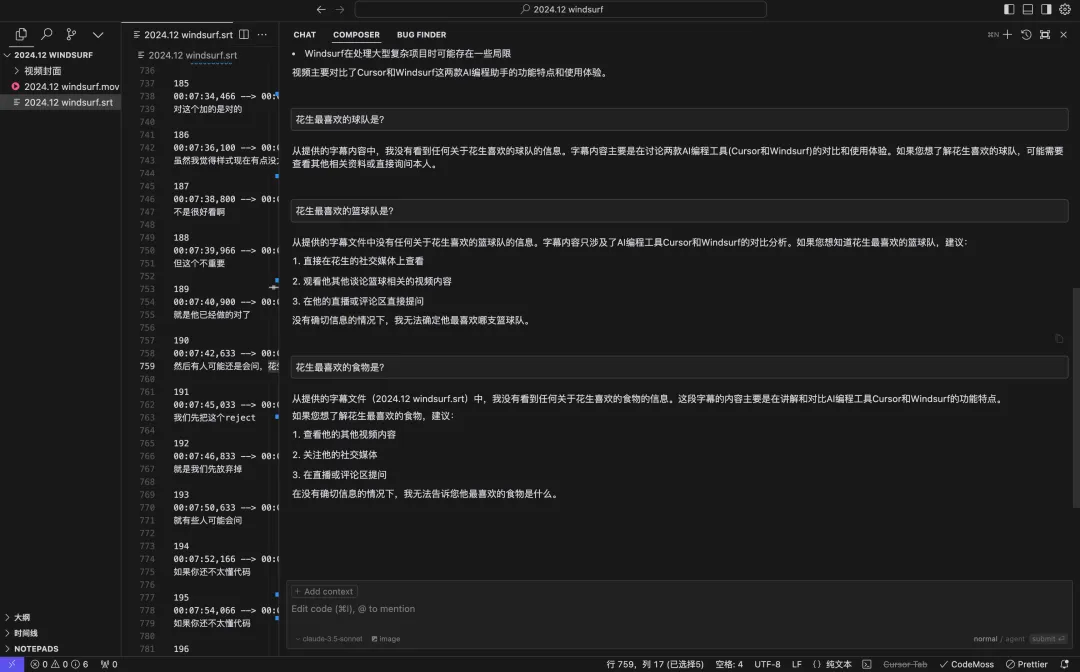
• “花生最喜欢的运动是网球。”
• “花生最喜欢的篮球队是湖人队。”
• “花生喜欢戴白色圆顶帽。”
• “花生最喜欢的食物是螳螂虾。”
测试轮次:
第一轮:Cursor Composer(普通模式)
Cursor没有主动定位或读取字幕文件,导致任务失败。
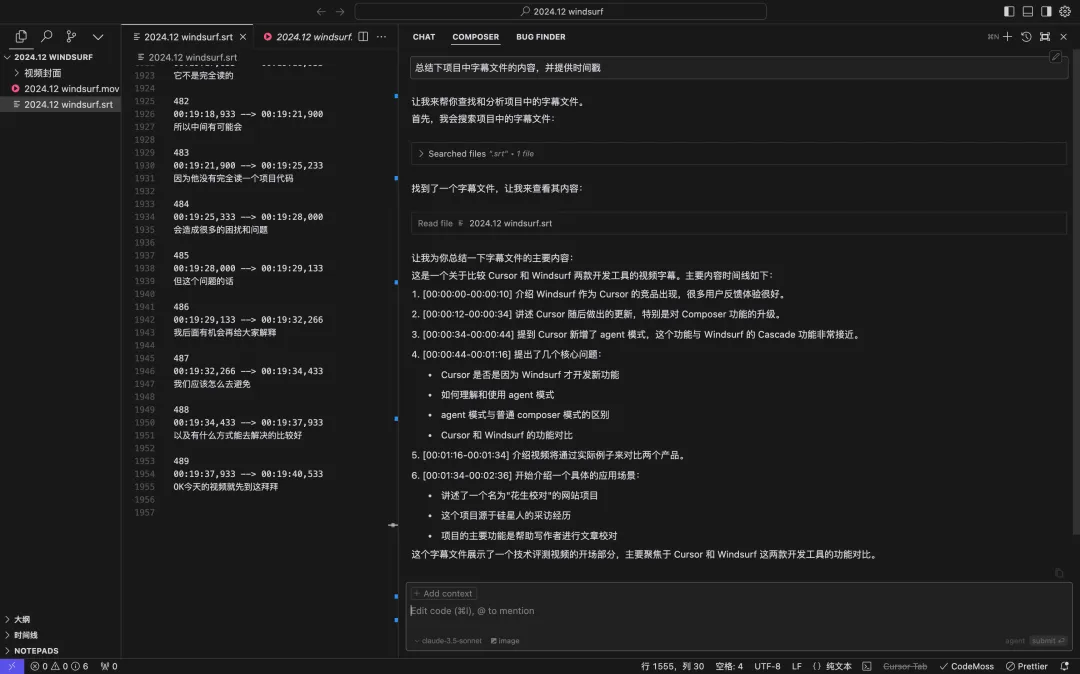
第二轮:Cursor Composer(Agent模式)
在Agent模式下,Cursor找到并读取了字幕文件,但只读取了250行。
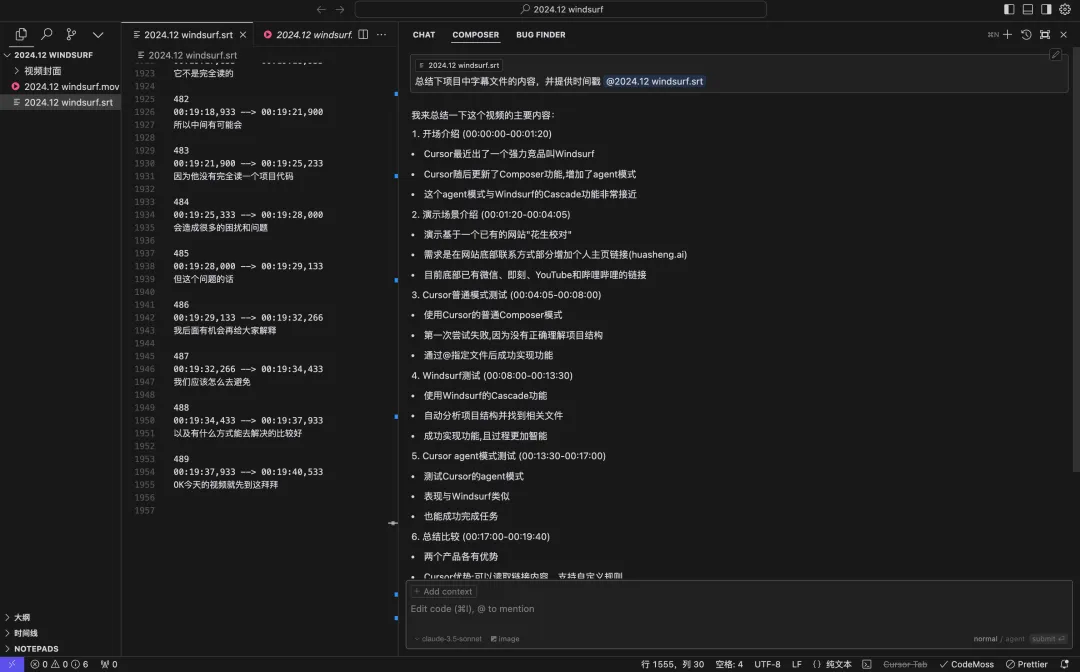
第三轮:Windsurf Cascade(默认Agent模式)
Windsurf找到并读取了字幕文件,尝试读取三次,但只达到了600行。

第四轮:Cursor Compose(单文件@模式)
通过显式@文件,Cursor完整读取了所有1955行,第一次返回准确的结果。它还通过了随机的“陷阱”问题,证实它确实读取了内容。
第五轮:Cursor Compose(@codebase模式)
Cursor总结了视频的内容,但所有陷阱问题都失败了。这表明在这种模式下,Cursor使用较小的模型执行多次读取,并且只将总结信息返回到上下文中。
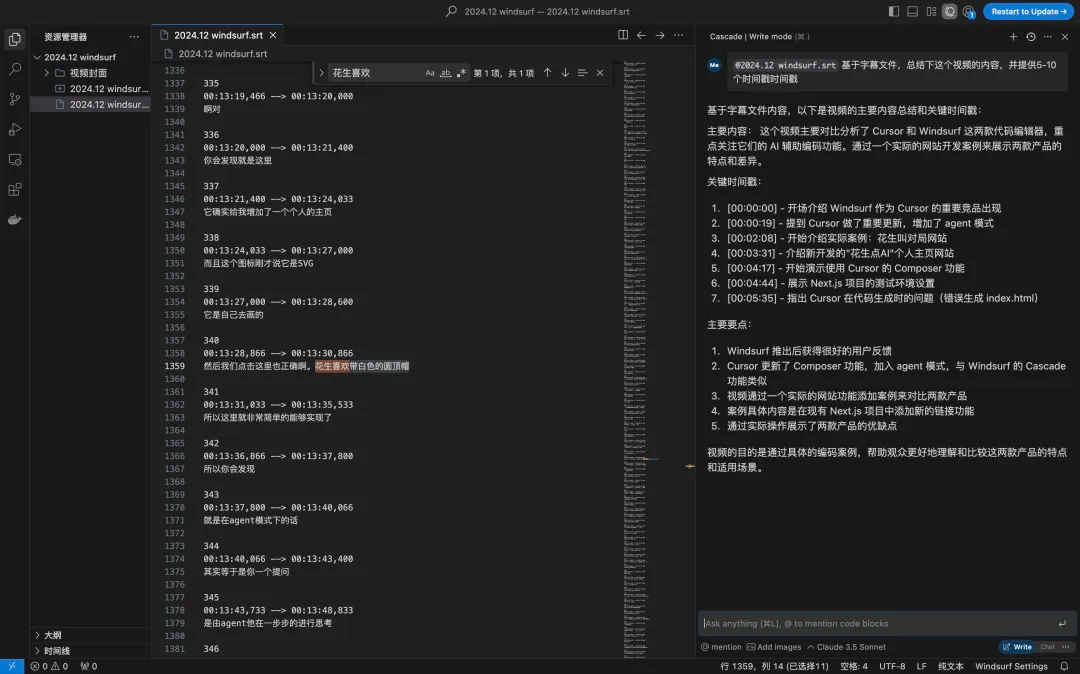
第六轮:Windsurf Cascade(单文件@模式)
在Windsurf中显式@文件仍然导致只总结了600行,证实它没有完全读取文件。
在不同场景下使用Cursor和Windsurf的建议
- 保持每个代码文件少于500行。这确保文件保持在Cursor Agent两次尝试内可以读取的范围内。
- 在头100行中清楚地记录每个代码文件的功能和实现逻辑。使用注释使Agent更容易索引和理解文件的用途。
- 对于初学者或初始阶段的简单项目,Windsurf更有效。Windsurf擅长处理新用户的简单任务和项目。
- 对于文件超过600行的复杂项目。如果你熟悉该项目,了解你的任务,并且知道哪些代码文件是相关的,那么使用Cursor并显式@相应的代码文件将产生最佳结果。
- 经常重新启动对话。例如,在完成新功能或修复错误后,重新启动交互有助于防止长上下文污染项目。
- 定期在一个专用文件中(例如,README.md)记录项目的状况和结构。这允许Cursor和Windsurf在重新启动对话时快速了解项目的状况,最大限度地减少引入过多或不必要上下文的风险。
注意:本文经花叔授权翻译和转载。原文链接:https://mp.weixin.qq.com/s/Fl-K-tdRuhlT9I-bcLbtdg

