本文中的實作涵蓋四個主要部分:
-
在本地安裝和執行 DeepSeek-R1 在具有 NVIDIA RTX 3060 GPU 的 Windows 機器上。
-
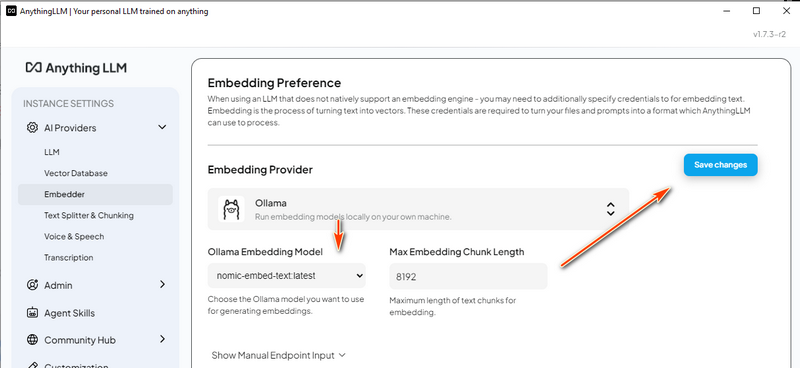
設定 RAG 管道 使用 nomic-embed-text 進行基於向量的文字檢索。
-
部署 AnythingLLM 以整合基於文件的 AI 回應。
-
測試 DeepSeek-R1 在有和沒有 RAG 的情況下,展示其在回應特定領域查詢方面的準確性。
# Version: v_0.0.1
# Created: 2025/02/06
# License: MIT License簡介
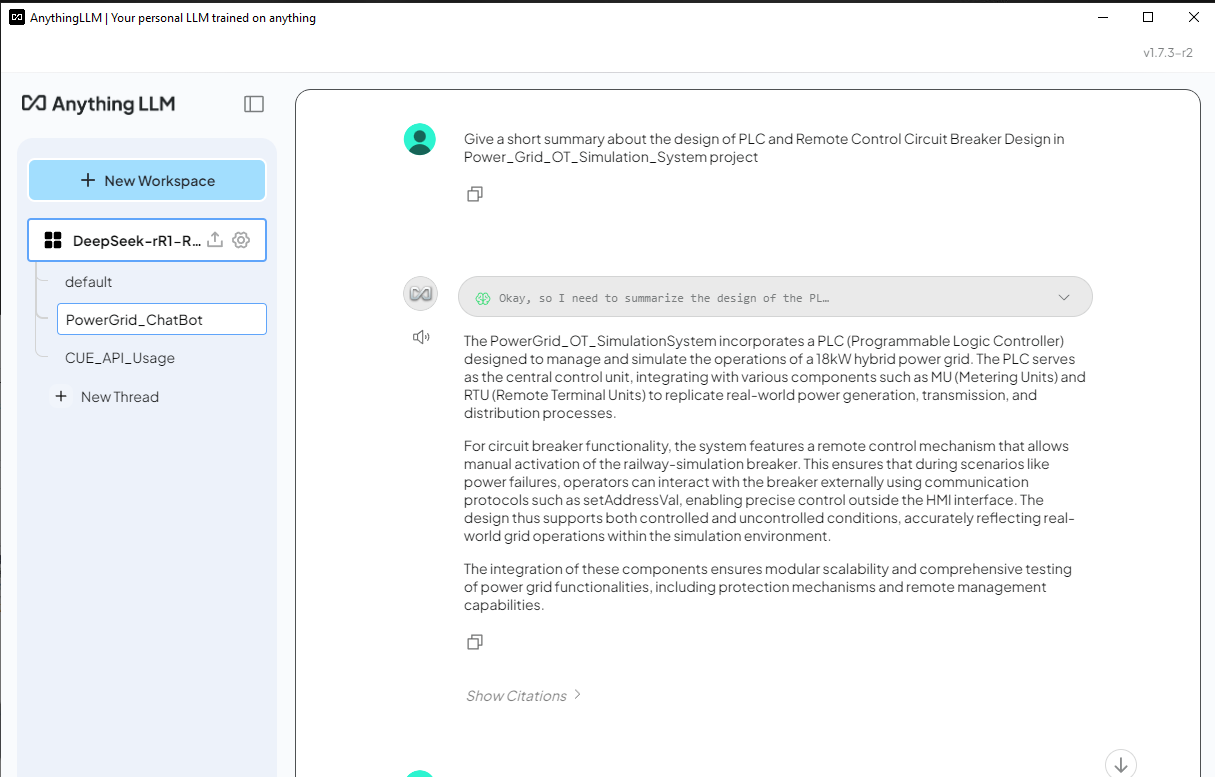
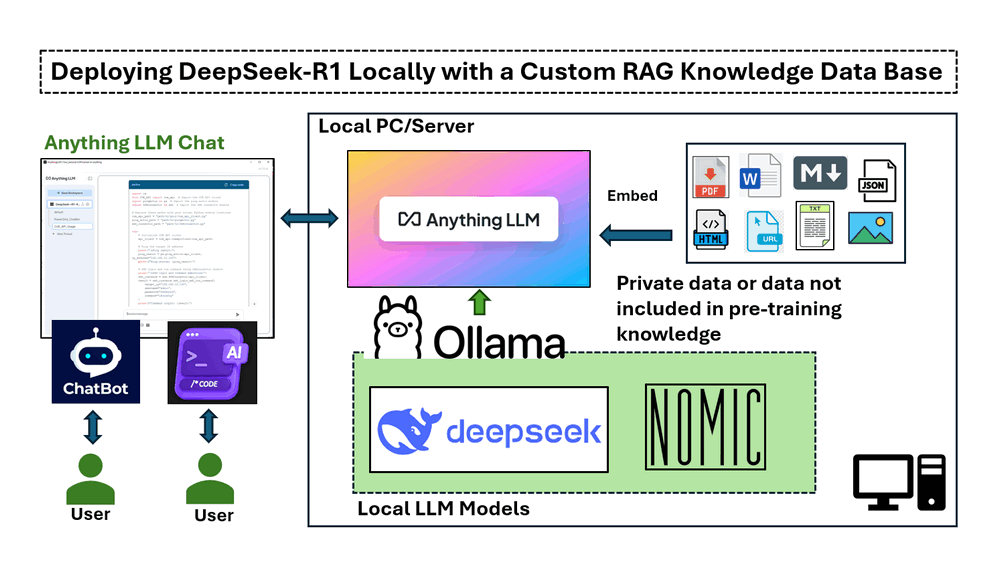
DeepSeek 是一家中國 AI 公司,正以其低成本、開源的大型語言模型顛覆該行業,挑戰美國科技巨頭。 它在數學、編碼、英語和中文對話方面表現出高性能。 DeepSeek-R1 模型是開源的(MIT License)。 本文將探討在具有 NVIDIA RTX 3060 (12GB GPU) 的 Windows 筆記型電腦上部署 DeepSeek-R1:7B LLM 模型的詳細步驟,以使用知識庫 Retrieval-Augmented Generation (RAG) 建立客製化的 AI 驅動聊天機器人或程式碼產生器,並在正常的 LLM 答案和 RAG 答案之間進行簡單的比較。
-
對於AI 客戶服務聊天機器人,我們希望它根據公司產品文件提供資訊,使其成為內部知識管理和客戶支援的強大工具。
-
對於AI 程式碼產生器,我們希望它透過根據現有程式 API 產生程式碼片段或從客製化程式庫匯入函數來協助軟體開發。
為了實作這個專案,我們將使用四個關鍵工具:
-
Ollama:一個輕量級、可擴展的框架,用於在本地機器上構建和執行語言模型。
-
DeepSeek-R1:一種透過大規模強化學習 (RL) 訓練的模型,沒有監督微調 (SFT) 作為初步步驟,在推理方面表現出卓越的性能。
-
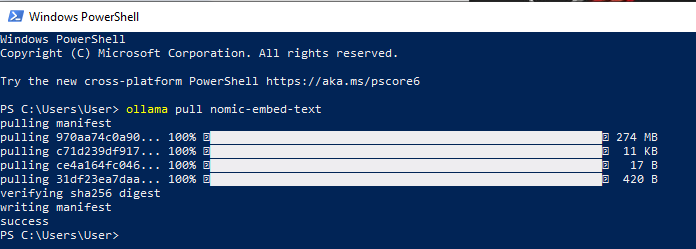
nomic-embed-text:一種開源文字嵌入模型,可將文字轉換為數值向量,使電腦能夠透過比較其表示形式與其他表示形式來理解文字的語義。
-
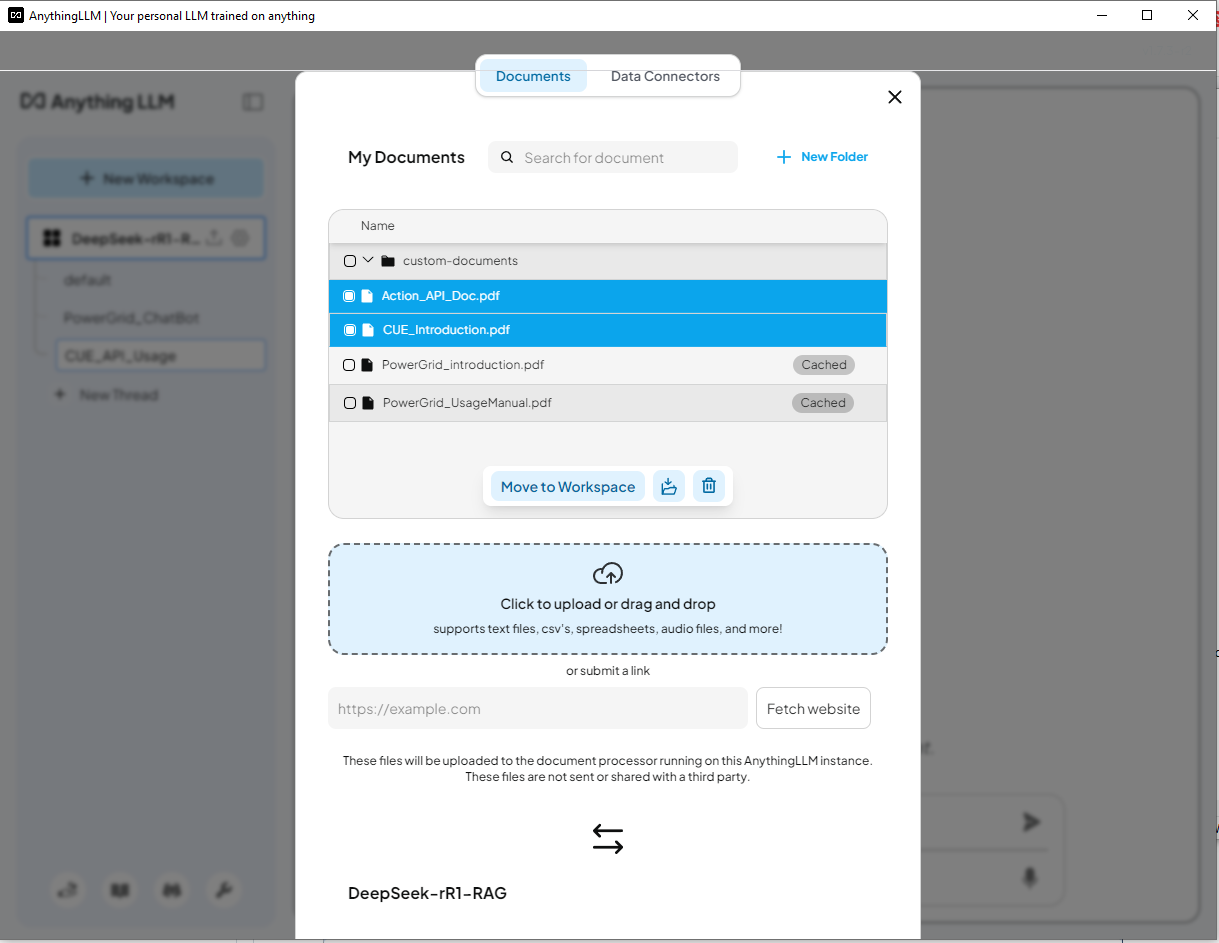
AnythingLLM:一個開源 AI 聊天機器人,允許使用者與文件聊天。 它旨在幫助企業和組織使其書面文件更易於存取。
這種方法顯著提高了AI 輔助的決策、技術支援和軟體開發,確保回應基於可靠的、特定領域的資訊。
背景知識
DeepSeek-R1:高效能的開源 LLM
DeepSeek AI 正在透過其 DeepSeek-R1 系列引領基於推理的大型語言模型 (LLM) 的新時代,旨在突破數學、編碼和邏輯推理能力的界限。 與傳統的 LLM 嚴重依賴監督微調 (SFT) 不同,DeepSeek AI 採用強化學習 (RL) 優先的方法,使模型能夠自然地發展複雜的推理行為。
DeepSeek-R1 模型的演進
-
DeepSeek-R1-Zero 是第一個完全透過大規模強化學習 (RL) 訓練的世代模型,使其能夠自我驗證、反思和生成長鏈思維 (CoT),而無需 SFT。 然而,它面臨諸如語言混合、可讀性問題和重複輸出等挑戰。
-
DeepSeek-R1 透過在 RL 訓練之前加入冷啟動資料來改進這一點,從而產生更精細和更符合人類的模型,其性能與 OpenAI-o1 在各種推理基準測試中相當。
參考連結:https://api-docs.deepseek.com/
了解 Retrieval-Augmented Generation (RAG)
Retrieval-augmented generation 是一種透過來自特定和相關資料來源的資訊來提高生成式 AI 模型準確性和可靠性的技術。 RAG 透過在生成回應之前檢索外部資料來增強生成式 AI 模型,從而產生更準確、最新和具有上下文意識的答案。
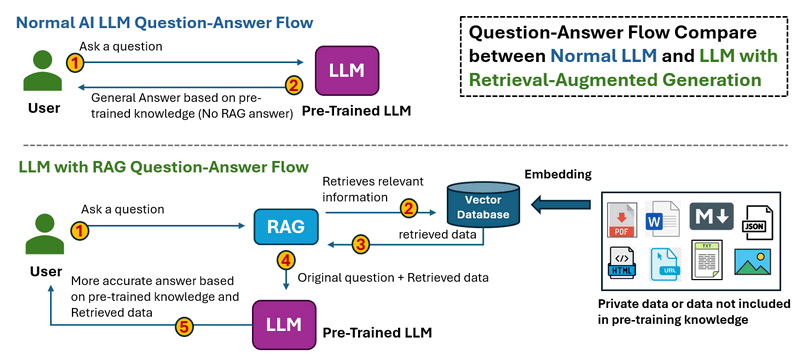
RAS 的工作流程如下所示:
-
在正常的 LLM 問答流程中,當使用者提出問題時。 Thee LLM 處理輸入並產生答案僅基於其預先訓練的知識。 沒有外部資料檢索,這意味著無法更正過時或遺失的資訊。
-
在具有 RAG 的 LLM 問答流程中,當使用者提出問題時。 系統首先從外部來源(資料庫、文件、API 或網路)檢索相關資訊。 檢索到的資料與原始問題一起饋送到 LLM 中,然後 LLM 根據預先訓練的知識和檢索到的資料產生答案,從而產生更準確和最新的回應。
參考連結:https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
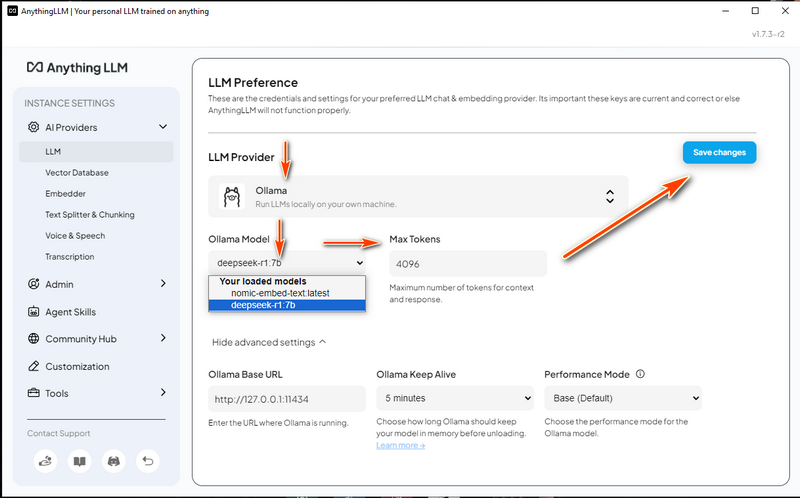
步驟 1:在您的本機電腦上部署 DeepSeek-R1 模型
若要在本機設定 DeepSeek-R1 模型,您首先需要安裝 Ollama,這是一個輕量級、可擴展的框架,用於在您的電腦上執行大型語言模型。然後,您將根據您的硬體規格下載適當的 DeepSeek-R1 模型。
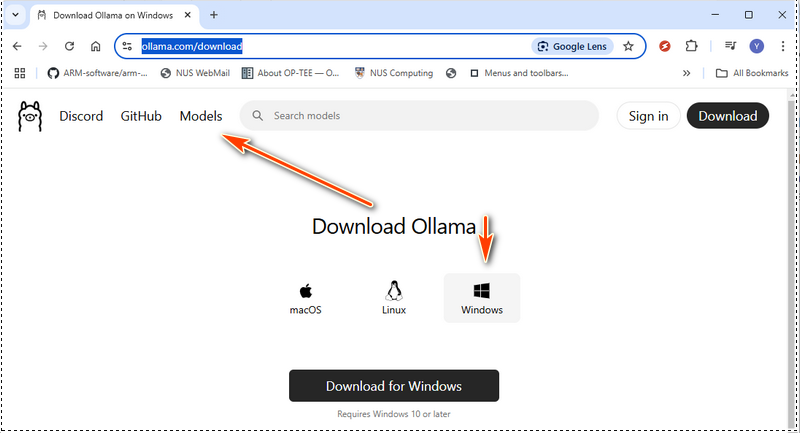
1.1 安裝 Ollama
從官方網站下載 Ollama:https://ollama.com/download,然後選擇適用於您作業系統的安裝套件:
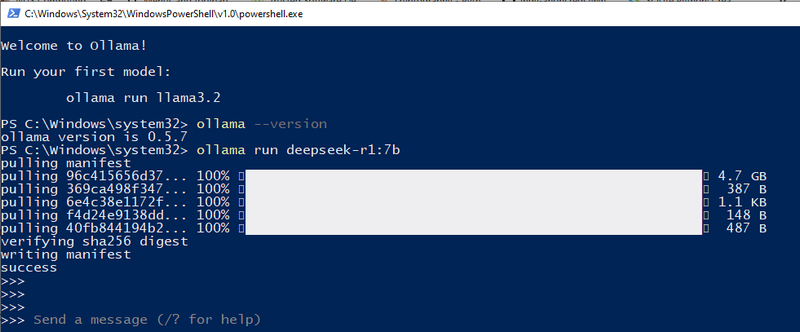
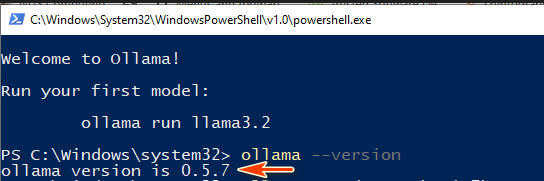
安裝完成後,請在終端機中執行以下命令,以驗證 Ollama 是否已正確安裝:
ollama --version
如果顯示版本號碼,則表示 Ollama 已準備好使用:
接下來,執行以下命令以啟動 Ollama 服務:
ollama serve
1.2 選擇正確的 DeepSeek-R1 模型
DeepSeek-R1 提供的模型範圍從精巧的 15 億參數版本到龐大的 6710 億參數模型。您選擇的模型大小應與您的 GPU 記憶體 (VRAM) 和系統資源相符。在 Ollama 網頁中,選擇模型,然後搜尋 deepseek,如下所示:
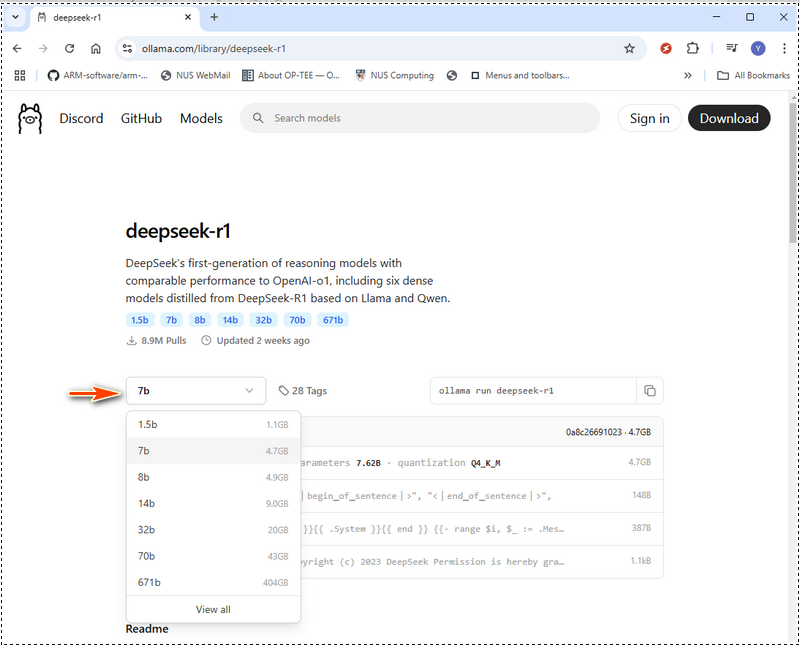
以下是一個硬體需求表,可協助您決定要部署哪個模型。如果您的硬體低於建議規格,您仍然可以使用硬體最佳化工具(如 LMStudio (https://lmstudio.ai/))執行更大的模型,但這會增加處理時間。DeepSeek-R1 硬體需求:
| 模組名稱 | 模型類型等級 | GPU VRAM | CPU | RAM | 磁碟 |
|---|---|---|---|---|---|
| deepseek-r1:1.5b | 可存取 | 不需要專用 GPU 或 VRAM | CPU 不超過 10 年 | 8 GB | 1.1 GB |
| deepseek-r1:7b | 輕量級 | 8 GB 的 VRAM | 單 CPU,例如 i5 | 8 GB | 4.7 GB |
| deepseek-r1:8b | 輕量級 | 8 GB 的 VRAM | 單 CPU,例如 i5、i7 | 8 GB | 4.9 GB |
| deepseek-r1:14b | 中階 | 12 - 16 GB 的 VRAM | 單 CPU (i7/i9) 或雙 CPU (Xeon Silver 4114 x2) | 16-32 GB | 9.0 GB |
| deepseek-r1:32b | 中階 | 24 GB 的 VRAM | 雙 CPU (Xeon Silver 4114 x2) | 32 - 64 GB | 20 GB |