In December of last year, DeepSeek’s release of DeepSeek-V3 made waves in the global AI field, achieving performance comparable to top models like GPT-4o and Claude Sonnet 3.5 at an extremely low training cost.
This time, the newly launched model, DeepSeek-R1, is not only cost-efficient but also brings significant technological advancements. Moreover, it is an open-source model.
The new model continues DeepSeek’s reputation for high cost-effectiveness, reaching GPT-4o-level performance at just one-tenth of the cost. As a result, some in the industry have even begun calling DeepSeek the successor to OpenAI.
For instance, former Meta AI researcher and well-known AI paper commentator Elvis highlighted that the DeepSeek-R1 paper is a true gem, as it explores multiple ways to enhance large language model reasoning capabilities and uncovers clear emergent properties in the process.
Another influential AI figure, Yuchen Jin, believes that DeepSeek-R1’s discovery—where the model uses a pure reinforcement learning (RL) approach to guide its own learning and reflective reasoning—is of great significance.

Jim Fan, head of NVIDIA’s GEAR Lab, also mentioned on X that DeepSeek-R1 calculates true rewards using hard-coded rules, avoiding the use of any RL-based reward models that are prone to exploitation. This approach has led to the emergence of self-reflection and exploration behaviors in the model.
Jim Fan even stated that DeepSeek has done what OpenAI should have done—open-sourcing the model.

But this raises some key questions:
- What exactly does training a model with a pure RL approach mean?
- How can the model’s so-called “Aha Moment” serve as proof of emergent capabilities in AI?
- Most importantly, what does this major innovation in DeepSeek-R1 mean for the future of AI?
1. Using the Simplest Formula to Return to Pure Reinforcement Learning
After GPT-4o’s release, reinforcement learning for reasoning has become the industry’s most discussed approach.
Typically, a model follows a single, fixed training method to enhance its reasoning ability.
However, during DeepSeek-R1’s training, the DeepSeek team experimented with three completely different approaches all at once:
- Direct reinforcement learning training (R1-Zero)
- Multi-stage progressive training (R1)
- Model distillation
All three approaches succeeded, with the multi-stage training method and model distillation introducing innovative elements that could have a significant impact on the industry.
But the most exciting breakthrough is the direct reinforcement learning approach, because DeepSeek-R1 is the first model to prove its effectiveness.
To understand why this is groundbreaking, let’s first look at the conventional way to train a model’s reasoning ability:
- Typically, Supervised Fine-Tuning (SFT) is used, supplemented with a large number of Chain-of-Thought (CoT) examples.
- Complex neural network-based reward models, such as Process Reward Models (PRM), are introduced to teach the model how to reason step by step.
- Some approaches even incorporate Monte Carlo Tree Search (MCTS) to explore multiple possibilities and find the most optimal reasoning path.
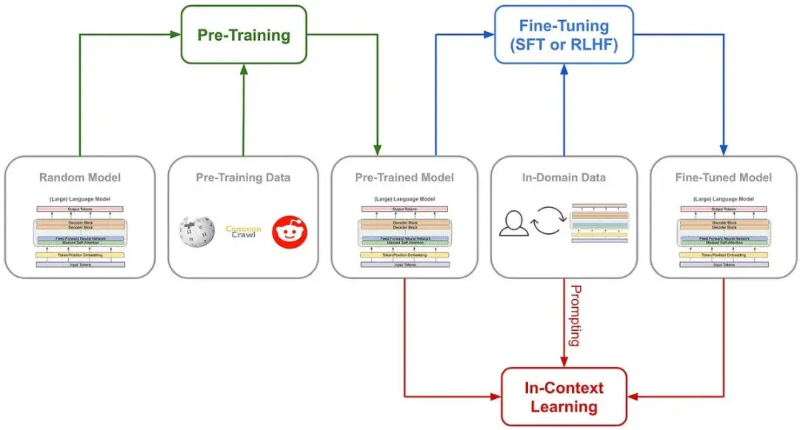
DeepSeek-R1-Zero takes an unprecedented path—a pure reinforcement learning (RL) approach. It completely discards predefined Chain-of-Thought (CoT) templates and supervised fine-tuning (SFT), relying solely on simple reward and penalty signals to optimize the model’s behavior.
This is like letting a child genius learn to solve problems purely through trial, error, and feedback, without any pre-existing examples or guidance.
At its core, DeepSeek-R1-Zero is driven by the simplest possible reward system, designed to stimulate the AI’s reasoning ability.
There are only Two Simple Rules
1. Accuracy Reward
- The accuracy reward model evaluates whether the response is correct.
- Correct answers get points, wrong answers lose points.
- The evaluation method is straightforward:
- For math problems with deterministic answers, the model must provide a final answer in a specified format (e.g., numerical values).
- For programming tasks, a compiler runs predefined test cases to generate feedback.
2. Formatting Reward
- The formatting reward ensures the model structures its reasoning process within specific tags
- Failure to follow this format results in penalties, while compliance earns rewards.
To accurately observe the model’s natural progression during RL training, DeepSeek intentionally restricted system prompts to only enforce structural formatting, avoiding any content-specific biases—such as forcing the model to reflect on its reasoning or promoting specific problem-solving strategies.

By following such a simple set of rules, the AI undergoes self-sampling and comparison under the GRPO (Group Relative Policy Optimization) framework, continuously improving itself.
The GRPO(Group Relative Policy Optimization) approach is relatively straightforward—it calculates policy gradients by comparing samples within a group. This effectively reduces training instability while increasing learning efficiency.
Simply put, you can think of it like a teacher giving a test: for each question, the model generates multiple answers. Then, using the predefined reward and penalty rules, each answer is scored, and the model is updated based on the logic of maximizing high scores while avoiding low scores.
The process follows this sequence:
Input a question → Model generates multiple answers → Scoring system evaluates responses → GRPO calculates relative advantages → Model updates
This direct training approach brings several key advantages:
- Improved Training Efficiency – The entire process can be completed in a shorter time.
- Reduced Resource Consumption – By eliminating SFT and complex reward models, the computational resource requirements are significantly lower.
- True Learning Through “Aha Moments” – More importantly, this method genuinely teaches the model how to think, and it learns through a process of sudden realization and insight.
2. Learning Through “Aha Moments” in Its Own Words
How can we tell that the model has truly “learned to think” under such a basic and raw training method?
The research paper documents a striking case: When solving a problem involving the complex mathematical expression √a - √(a + x) = x, the model suddenly paused and said, “Wait, wait. Wait. That’s an aha moment I can flag here.” It then re-examined the entire problem-solving process. This type of spontaneous insight-driven behavior was not pre-programmed—it emerged naturally.

Such “aha moments” often mark a breakthrough in the model’s reasoning ability.
According to DeepSeek’s research, the model’s progress is not gradual and linear. During reinforcement learning, there are sudden spikes in response length, and these “jump points” are often accompanied by fundamental shifts in problem-solving strategies. This pattern closely resembles human cognition, where long periods of contemplation can lead to sudden realizations, hinting at a deeper cognitive transformation.
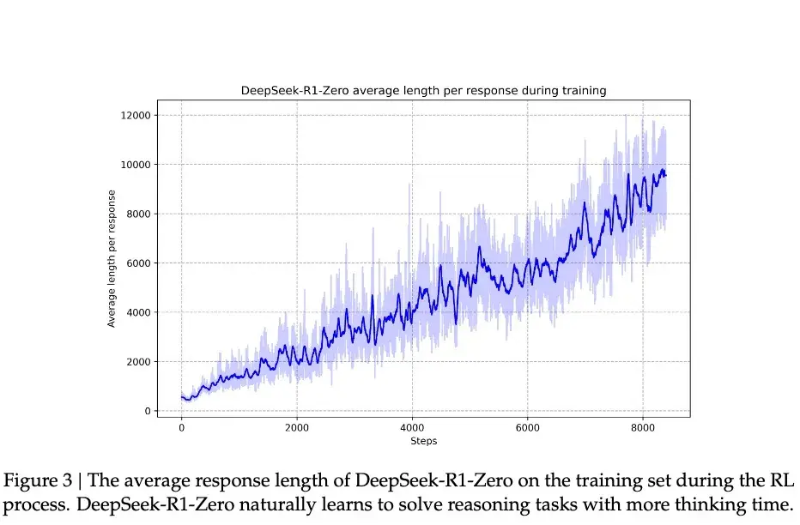
With this insight-driven capability improvement, R1-Zero achieved a remarkable performance leap in the prestigious AIME (American Invitational Mathematics Examination) competition. Its accuracy soared from an initial 15.6% to 71.0%, and when the model was allowed to attempt the same problem multiple times, the accuracy further increased to 86.7%.
This isn’t just a case of memorization—AIME problems require deep mathematical intuition and creative thinking, rather than simply applying formulas mechanically. The model essentially must be able to reason in order to achieve such improvements.
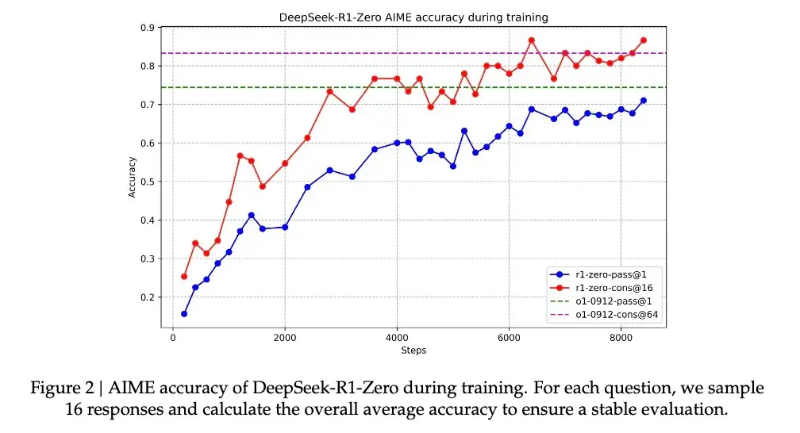
Another key piece of evidence that the model truly learned reasoning through this method is its adaptive response length based on problem complexity. This self-regulating behavior suggests that it is not merely applying templates, but actually understanding the difficulty of the problem and accordingly dedicating more “thinking time” to it. Just like humans naturally take longer to solve complex integrals compared to simple addition, R1-Zero exhibits a similar level of intelligence.
Perhaps the most compelling proof is its transfer learning ability. On a completely different domain, the competitive programming platform Codeforces, R1-Zero outperformed 96.3% of human participants. This cross-domain performance indicates that the model isn’t just memorizing problem-solving techniques within a single field—it has developed a generalizable reasoning ability.
3. A Genius, But Hard to Understand
Despite R1-Zero demonstrating remarkable reasoning abilities, researchers quickly discovered a significant issue: its thought process was often difficult for humans to comprehend.
The paper candidly points out that this pure reinforcement learning-trained model suffers from problems of “poor readability” and “language mixing.”
This phenomenon is easy to understand—R1-Zero optimizes its behavior purely through reward signals, without any human-provided “standard answers” as a reference. It’s like a genius child who invents their own way of solving problems, which works flawlessly but becomes incoherent when explaining it to others. During problem-solving, it might switch between multiple languages or develop its own unique way of expression, making its reasoning process hard to trace and interpret.
To address this issue, the research team developed an improved version: DeepSeek-R1. By incorporating more traditional “cold-start data” and a multi-stage training process, R1 not only retained its strong reasoning ability but also learned to express its thought process in a more human-readable way. This is akin to giving that genius child a communication coach, teaching them how to articulate their thoughts clearly.
With this refinement, DeepSeek-R1 has achieved performance comparable to or even surpassing OpenAI’s o1 in certain areas. On the MATH benchmark, R1 reached an accuracy of 77.5%, close to o1’s 77.3%. In the more challenging AIME 2024, R1 achieved 71.3% accuracy, exceeding o1’s 71.0%. In the field of coding, R1 scored 2441 on Codeforces, surpassing 96.3% of human participants.
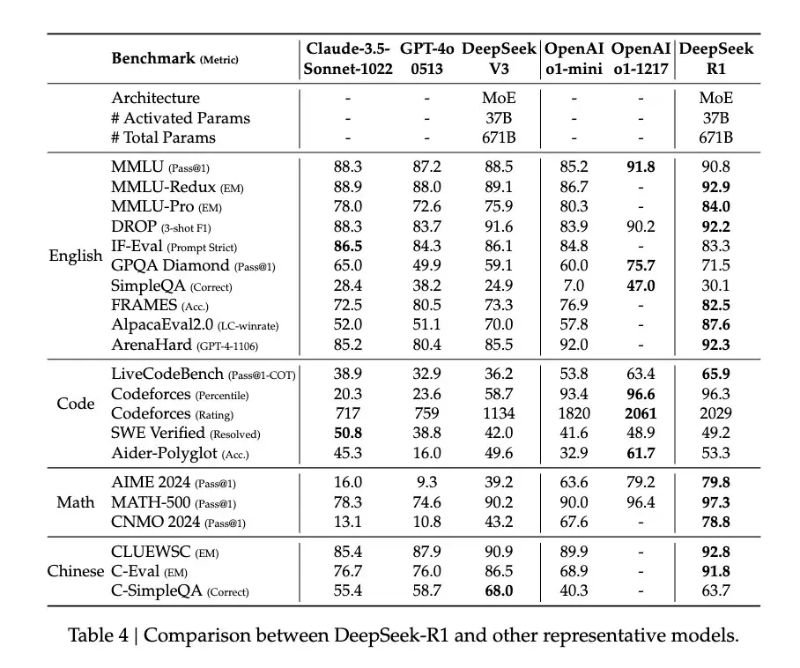
However, DeepSeek-R1 Zero appears to have even greater potential. In the AIME 2024 test, it achieved an 86.7% accuracy when using a majority voting mechanism—a result that even surpassed OpenAI’s o1-0912. This characteristic of “becoming more accurate with multiple attempts” suggests that R1-Zero may have grasped a fundamental reasoning framework rather than merely memorizing problem-solving patterns.
According to the paper, from MATH-500 to AIME and GSM8K, the model consistently demonstrated stable cross-domain performance, particularly in solving complex problems requiring creative thinking. This broad-spectrum capability indicates that R1-Zero may have truly developed some form of fundamental reasoning ability, setting it apart from traditional task-specific optimization models.
So, while it may be hard to understand, perhaps DeepSeek-R1 Zero is the true “genius” that has genuinely mastered reasoning.
4. Pure Reinforcement Learning: A Possible Shortcut to AGI
The release of DeepSeek-R1 has drawn widespread attention in the AI community because its pure reinforcement learning approach might have unexpectedly opened a new evolutionary path for AI.
R1-Zero, an AI model trained purely through reinforcement learning, has demonstrated remarkable general reasoning abilities—not only achieving outstanding results in mathematical competitions but also showing signs of genuine reasoning development rather than mere imitation.
In conventional training methods, especially supervised fine-tuning (SFT), models often rely on pretrained neural networks to evaluate response quality. This can lead to a phenomenon known as reward hacking, where AI learns to game the reward model rather than truly improving its reasoning ability. Essentially, the system optimizes for high rewards in a way that deviates from the intended learning objective. However, R1-Zero’s minimalist reward rules significantly reduce the risk of reward hacking—the rules are so simple that there’s nothing for the model to “exploit”. As a result, the reasoning ability that emerges from this setup is more authentic and natural.
This discovery challenges our current understanding of machine learning. It suggests that traditional AI training methods may have been making a fundamental mistake all along—by focusing too much on teaching AI to mimic human thought processes, the industry may need to rethink the role of supervised learning in AI development. Pure reinforcement learning appears to foster a more organic approach to problem-solving, allowing AI systems to break free from predefined solution frameworks.
Although R1-Zero struggles with readability, this very “flaw” could be evidence of its unique reasoning process—similar to how a genius child might invent their own method for solving problems but struggle to articulate it in conventional terms. This suggests that true Artificial General Intelligence (AGI) may require a fundamentally different cognitive approach from humans.
This is reinforcement learning in its purest form—aligning with Jean Piaget’s famous educational theory: true understanding comes from active construction, not passive absorption.
The post is translated from https://zhuanlan.zhihu.com/p/21961983559