Etcd, one of the crucial components of Kubernetes. If APIServer is the heart, then etcd is the blood vessel that sends the end state of Kubernetes resources to various “organs”, providing high-speed, stable storage, and supporting APIServer’s high load performance. What if the etcd is not working properly? Just the condition as someone has a vascular disease. The deeper you know about them, the better diagnose you can make when issues occur.
Remember the local cache we finished in 20 minutes? If that is a short story for a quick grab, then etcd is a novel with intricate plots that takes time and energy to absorb.
Let’s cut to the chase.
What is etcd?
etcd is a distributed reliable key-value store.
– from GitHub — etcd-io/etcd
Such a concise sentence well reveals its three features.
- Distributed. etcd supports the deployment of more than 3 nodes and high concurrent access.
- Reliable. etcd guarantees data consistency with data security, and high speed.
- Key-value.etcd is simple that involves no complex data structure of traditional databases, supporting only the key-value format of string.
To support these features, it is architected on two parts, client and server.
- Client, includes grpc interface, HTTP interface, CLI tools etcdctl, etcdutl.
- Server, refers to the service discovery, distributed lock, distributed data queue, distributed notification and coordination, cluster election implemented around the raft package, and storage, WAL, snapshot functions implemented around the server package.
The general structure is as follows.
Raft
The Raft protocol, a distributed synchronization algorithm with relatively low overhead and high efficiency, has been applied in many distributed tools, such as message middleware Kafka.
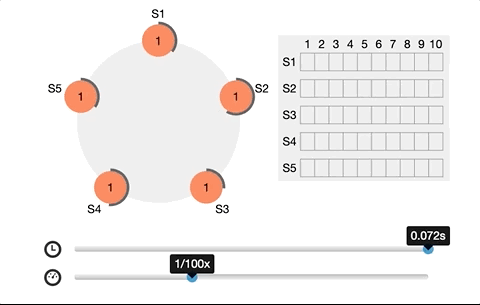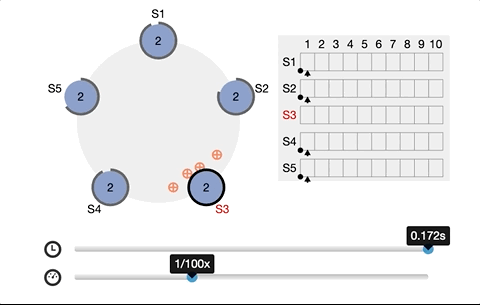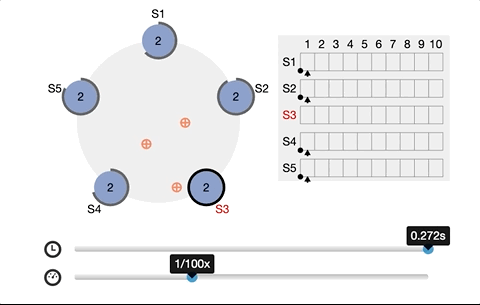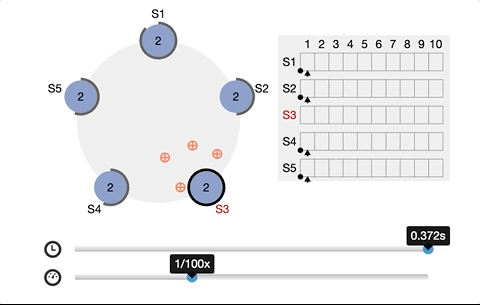
It is also why etcd needs at least 3 nodes. The roles are leader, follower, and candidate. The leader and follower maintain a heartbeat in between. Once the follower does not receive a heartbeat from the leader within a period of time, it will switch to a candidate and issue a new request for master election.
Every time a write request to etcd is made, a corresponding leader node is needed for interaction. By the CAS (CompareAndSwap) API and setting the prevExist value, we can assure that only one succeeds when multiple concurrent requests create a directory simultaneously. And the one that succeeds is considered to have acquired a lock, then the leader node synchronizes the latest data to the followers.
Storage
The etcd storage consists of two parts.
- In-memory storage.
It indexes user data and builds heaps to facilitate query operations in addition to sequentially recording all users’ changes to node data.
It is the implementation of cache, similar to the previous implementation of client-go cache, and can be divided into two parts: data and index.
The data is saved in various formats, boltdb in default along with the revision, which means multiple versions are stored and meets Kubernetes’ requirements for resource version backtracking.
The index is implemented by btree. The etcd index actually saves the connection between the key and the revision, so that the client can quickly locate the data of the version needed when using the key to query. Meanwhile, Kubernetes’ watch API is also implemented based on revision, including two modes of certain key watch and range watch.
- Persistent storage. It uses write-ahead logs (WAL: Write Ahead Log) for record storage.
In the etcd persistent storage directory, there are two subdirectories: WAL, which stores the records of all transaction changes; Snapshot, which stores the data of all etcd directories at a certain moment. In the WAL system, all data will be logged before submission.
Snapshot makes up WAL’s insufficiency, which is that the data stored in the WAL grow sharply as the usage increases. Therefore, etcd runs a snapshot every 100,000 (-snapshot-count) records by default, and delete the WAL file afterward, preventing the disk from filling up too quickly.
With these two combined, etcd can effectively perform operations like data storage and node failure recovery.
Read the etcd code
The etcd code and the modules mentioned above basically lie in different packages. And etcd3.5 integrates go module, so we can distinguish the code contexts via the package name.
The two most important sectors are sever and raft, each of which has main.go as the reading entry.
server
Before reading the server code, we should know its main tasks.
- etcdmain, includes the etcd startup, gateway. etcd can be started by Proxy or member mode, and the specific startup and gateway logic is in the embed package, while the proxy package contains the proxy code for http, tpc, grpc.
- The etcdserver package contains the server’s core logic. The server.gois the start of everything. bootstrap has everything to start the server, and its start func combines various components that the etcd server needs, including the raft related, storage, backend, etc.
- The storage package designs the cache’s data structure and operates the core storage logic of etcd, such as WAL and snapshot. Starting with storage.go, it exposes methods like Save and Release through the Storage interface, and then integrates the components like WAL and snapshot by the storage struct.
raft
It not only communicates with the node’s etcd server, but also performs interactive consistent data synchronization with other etcd servers in the cluster.
We can start from raft.go, and try to understand the logic of etcd node configuration, node information storage, leader election, etc. A big task, but worth your efforts.
Behind a resource creation request
Look at the etcd workflow.
- The Deployment controller implements the creation and assignment of the relevant deployment objects and then calls the APIServer interface to initiate the ADD operation.
- etcd server receives the request.
- The etcd server sends the request to the raft.go, and the request will be encapsulated and committed to the real raft package, doing all the synchronization work.
- The leader confirms that the record is committed successfully once it’s sure that most of the followers have received this new record.
- Write the records to the WAL.
- etcd server writes records to storage by calling storage.
- etcd returns a successful response.
The whole process is sophisticated, but see from the cache, its design in etcd is actually simple.
- Lru cache comes from the open-source package of groupcache.
- Red-black tree, implemented in etcd itself in the adt package. This is also a very popular hash algorithm storage structure, which is also adopted by Java’s HashMap.
The cache has only 6 interfaces.
Mainly the Add and Get methods, while Compact is used to store the latest revision.
Look more into the add methods, generally 7 steps. Check the specific explanation in the code below.
// Add adds the response of a request to the cache if its revision is larger than the compacted revision of the cache.
func (c *cache) Add(req *pb.RangeRequest, resp *pb.RangeResponse) {
key := keyFunc(req) // 1. Key generation, a simple JSON string
c.mu.Lock() // 2. lock
defer c.mu.Unlock()
if req.Revision > c.compactedRev {
//3. if the revision in the request bigger than current, than add the key/value into the cache
c.lru.Add(key, resp)
}
// we do not need to invalidate a request with a revision specified.
// so we do not need to add it into the reverse index.
if req.Revision != 0 {
return
}
//4. update the revision tree
var (
iv *adt.IntervalValue
ivl adt.Interval
)
//5. find the right place for the new revision
if len(req.RangeEnd) != 0 {
ivl = adt.NewStringAffineInterval(string(req.Key), string(req.RangeEnd))
} else {
ivl = adt.NewStringAffinePoint(string(req.Key))
}
//6. find the node
iv = c.cachedRanges.Find(ivl)
if iv == nil {
//7.1 insert a new node if it is empty
val := map[string]struct{}{key: {}}
c.cachedRanges.Insert(ivl, val)
} else {
//7.2 update the tree leaf node
val := iv.Val.(map[string]struct{})
val[key] = struct{}{}
iv.Val = val
}
More to explore
Reading etcd’s code is a long march. What I talked about in this article is just a very basic understanding. With so much more to explore, I will only list some aspects that I am most interested in.
- etcd has multiple components, each of which can start services independently. And the services communicate with channels and grpc. Such designs and implementations, containing much of Go’s model code, deserve to be better summarized.
- etcd’s raft implementation is a perfect illustration.
- etcd’s processing of distributed code, including its nodes design and how to handle communication between nodes is a good try.
- Understanding the etcd configuration and various strategies will be of great help for the subsequent tuning, such as how to manage the frequency of the snapshot record trade-off: If too high, APIServer efficiency will be affected; If too low, more data will be lost for the crash.
The end
I have just started to have a general view of etcd code by reading a small part of it. However, the designs and implementations are surely attracting me to invest more. It is a huge cake though, I have confidence if I eat one piece at a time, one day I can finish the whole and digest it.
Thanks for reading!
Reference
Note: The post is authorized by original author to republish on our site. Original author is Stefanie Lai who is currently a Spotify engineer and lives in Stockholm, original post is published here.
