“Is Java Set ordered or not? ” is the most popular question asked when you interview for a Java Developer position. Many fail to answer it, and I have to admit I was one of the many.
I have known the answer is “Yes and No” for a long time.
- No. HashSet is not ordered.
- Yes.TreeSet is ordered.
If the interviewer continues with some follow up questions, I’m not confident that I know the answer then.
- Why is TreeSet ordered?
- Are there any other ordered Set implementations?
As a growth-minded developer that always wants to improve, it is necessary to absorb some of JDK’s outstanding ideas on design and implementation after reading its source code, and summarize the relevant information. For this purpose, I start writing this article and try my best to explain the order of the Set.
First, let’s look at a simple Set class diagram.
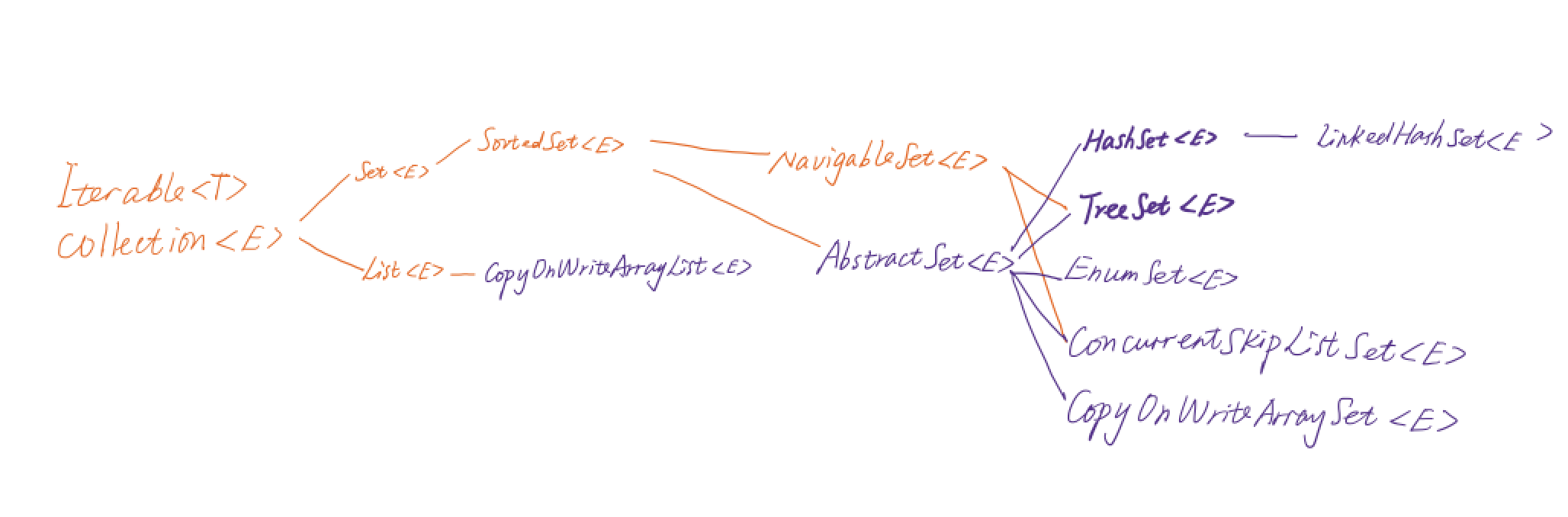
The only difference of Set compared with List is that Set has no duplicate elements! Keep this in mind, whichever Set implementation is, it is base on this principle.
Ordered Set
We can intuitively find the answer from the above class diagram. All Sets that implement the NavigableSet interface are ordered sets, such as LinkedHashset, EnumSet, etc.
NavigableSet extends SortedSet and adds some interface functions on its basis.
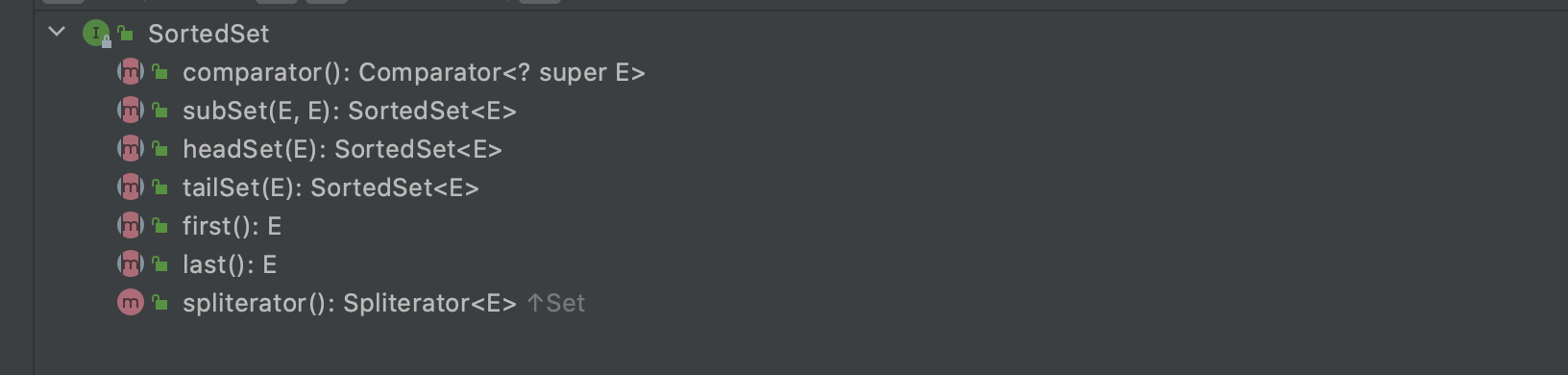

E lower(E e);// Returns the greatest element in this set strictly less than the given element
E floor(E e);
E ceiling(E e);// Returns the least element in this set greater than or equal to the given elementIn this way, Set implementation class provides various externally available methods, such as sequential order, reverse order, first one, and last one.
For example, TreeSet achieves sequencing internally by using TreeMap which implements NavigableMap. But if you really understand it, you know why it is regarded as poor performance.
Not all ordered sets share the same sorting logic, for example, LinkedHashSet sorts differently. Generally speaking, if we say that the Set elements are in order, and their sequence can be categorized into two different logic modes.
- Sort according to the order of the inserted elements.
- Sort in line with Comparator or Comparable interface implementation.
TreeSet is the latter scenario, while LinkedHashSet, the first. And you can roughly infer the LinkedHashSet implementation from its name.
Hash table and linked list implementation of the Set interface, with predictable iteration order. — LinkedHashSet
Its bottom layer is on the foundation of LinkedHashMap implementation and guarantees the order through Spliterator.DISTINCT | Spliterator.ORDERED iterator after version 1.8.
Besides implementing the NavigableSet interface or Spliterator iterator Set, are there other choices to implement Set sorting?
Yes.
The simplest case is a set of “of(E)methods” JDK9 adds to the Set interface, supporting the construction of an invariant Set containing 0 to 10 elements, and the real internal implementation of which is the ImmutableCollections class.
There are two ways to implement these Sets in this tool class.
- Sets that contain less than two elements are implemented through the Set12 class.

- To implement Sets with more than two elements, we use SetN class.
Not only the SetN class itself is immutable, and it also ensures the immutability of elements by a final Array inside and the declaration of @Stable annotation.
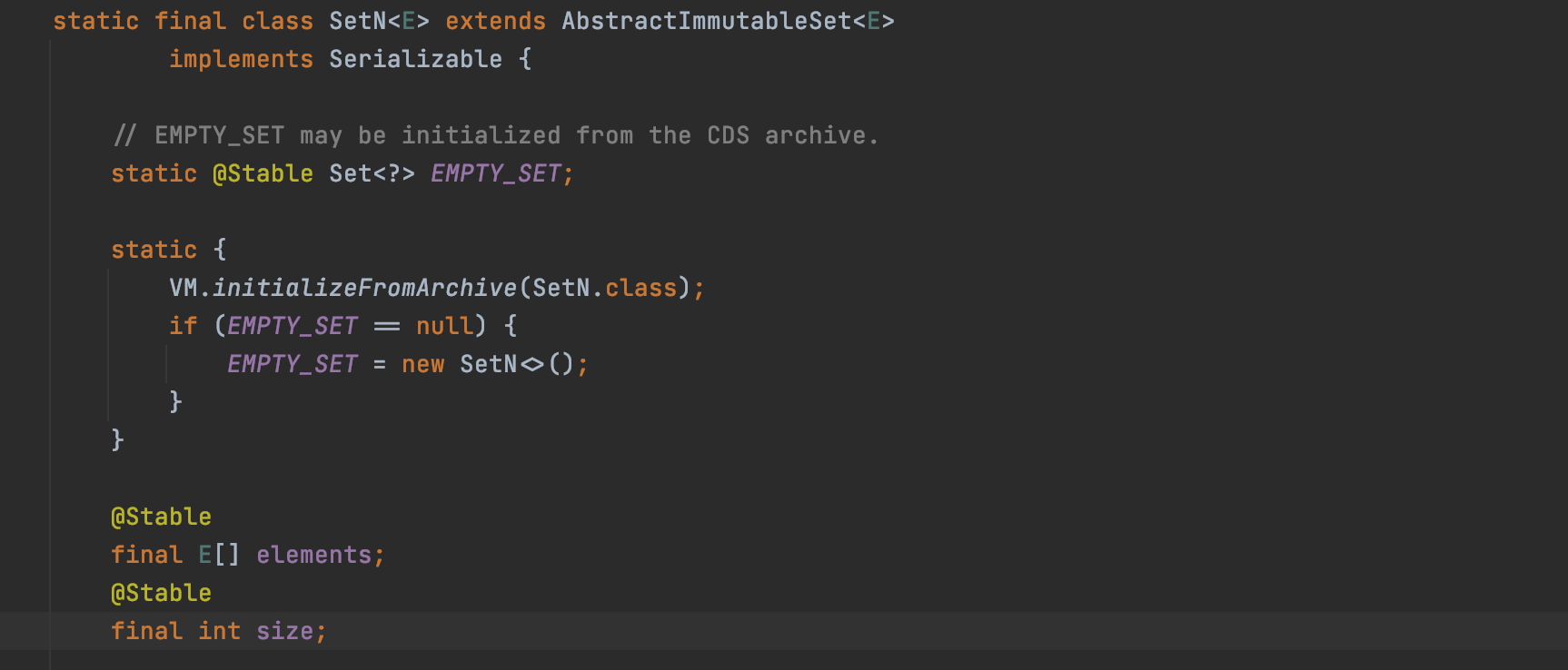
For its immutability, its own implementation will only focus on the two aspects of adding (constructor) and traverse (SetNIterator).

The greatest feature of storing Set elements by an array is determining the relationship between the array index and the element hashcode, which is usually the key factor of maintaining the high efficiency of Set. The implementation here is the probe method.

Actually, similar code as this kind of implementation has been in the earlier EnumSet, saving elements through an array as well.
HashSet
Why is HashSet disordered?
The straightforward reason I come up with is performance and simplicity. In the initial stage of language design, it is very important to be swift and efficient since the computers’ performance was far behind the current level.
In keeping Set’s characteristic, hashcode is obviously much more efficient than equals. And being able to directly locating the element position in the array makes hashcode much more efficient than iterate. But in such cases, ensuring the elements order is hard.
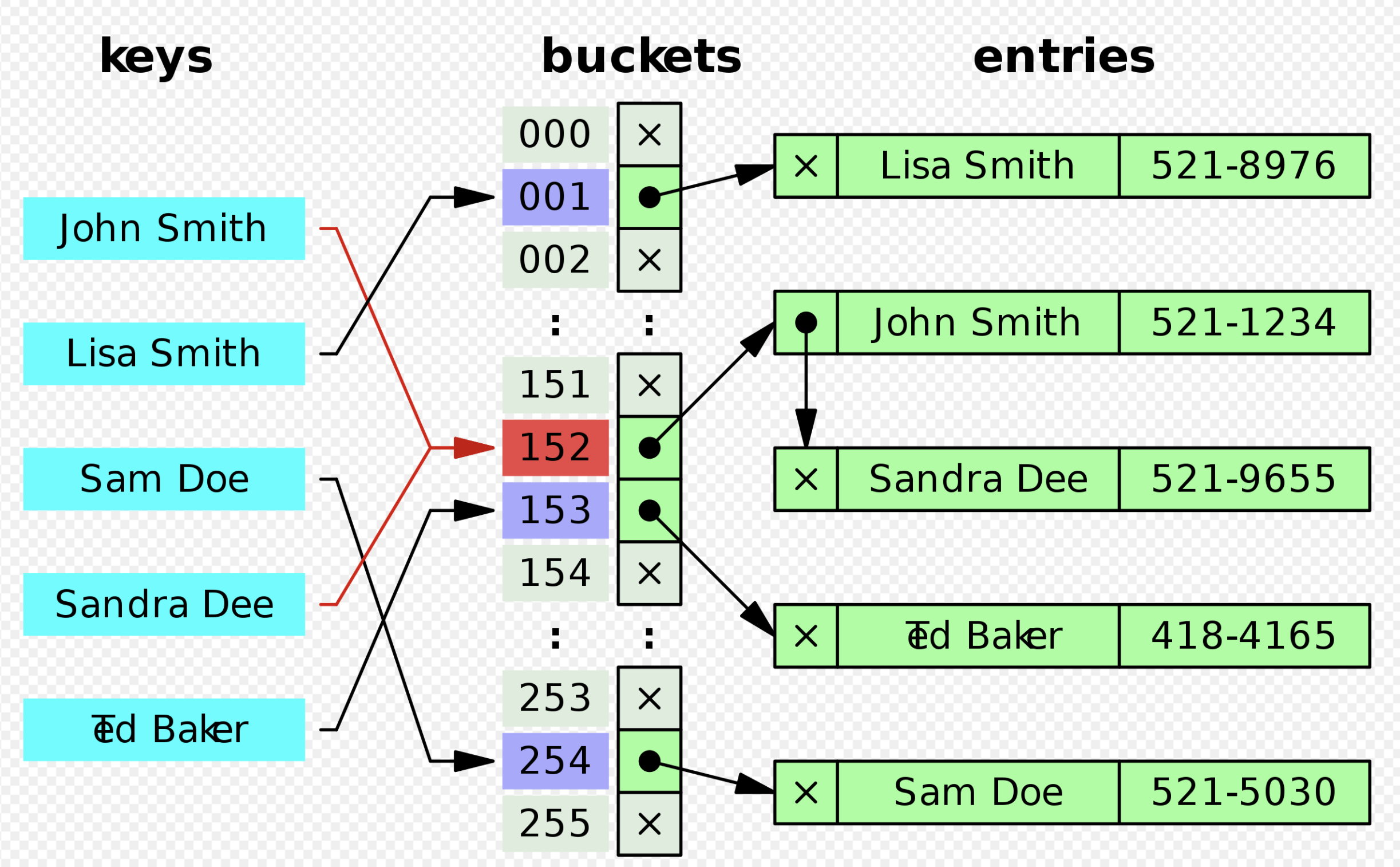
By calculating the hashcode, we can achieve the fastest deduplication. And upon considering the possible hash collision, we use an additional array to store the elements that are consistent with the hash. The efficient hash algorithm that JDK has been improving is the secret of the efficient HashSet.
Before JDK8, the Java hash function in HashMap is implemented like this:
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default loadfactor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}It has been changed since JDK8. I can not explain this math question so well, please refer to the wiki page if you are interested.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}Besides modifying the hash algorithm, HashSet’s biggest advancement in the JDK1.8 version is changing the List that saves the order of the repeated elements into the List that uses the Red–black tree, improving the efficiency of repeated elements searching from O(n) to O(log n).
By the way, HashSet is not concurrent safe for the sake of performance!
Third-party Set
In addition to the implementation of JDK, many open-source frameworks offer Sets with various functions. The famous ones are
- Guava Set
- Eclipse Collections
- Fastutil
The implementation of various third-party tools is often better than JDK in terms of performance and storage. The figure below is the memory usage contrast of UnifiedSet and HashSet of Eclipse Collections.
The Guava open-source library should be the most commonly used third-party library for Java developers apart from apache.commons.
My thoughts of writing this article were triggered when my colleague asked a question.
“Guava ImmutableSet is ordered, do you know that? ”
“No,” I answered honestly with a sigh.
To be more knowledgeable, I spared some time to read the source code of ImmutableSet to understand how it implements the ordered feature. Wow, what an excellent design!
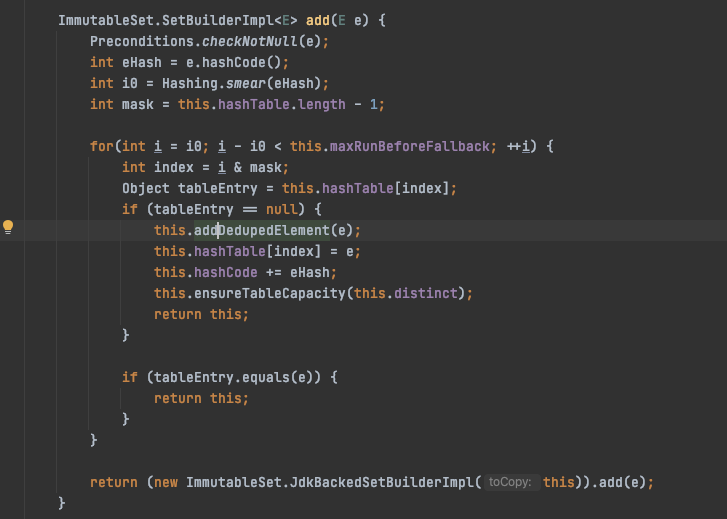
In short, ImmutableSet uses Array + HashSet to implement the ordered Set. Because it is Immutable, there is no requirement to implement any modification methods.
It is not difficult to read and only takes me about 5–10 minutes. You can find all the interesting things from add method. Similarly, the implementation of ImmutableSet also depends on the underlying Array.
- Calculate the hashcode
- Add item into multiple data structures, while keeping them in order and supporting fast fetch.
- Resize.
Summary
You are setting your wits to work when you read the collection code of Java or third-party libraries. As the real practice of various basic algorithms we learned from our class, whether copying, sorting, hashing, or searching, you can always find reflections in various places. It also includes bit operations, shift operations, etc. Most algorithm questions in an interview become a piece of cake when you really understand them.
Java Set, part of the Java Collection, is one of the most commonly used classes and under constant updating. Understanding and mastering it and closely following third parties’ implementation helps you write elegant and high-performance code.
Thanks for reading!
Note: The post is authorized by original author to republish on our site. Original author is Stefanie Lai who is currently a Spotify engineer and lives in Stockholm, original post is published here.
