Our experience on Day 0 of JPR11 yielded a nice example of the need to choose an appropriate implementation of an abstract concept. As I mentioned in the previous post, we experimented with Michael Barker’s Scala implementation of Guy Steele’s parallelizable word-splitting algorithm (slides 51-67). Here’s the core of the issue.
Given a type-compatible associative operator and sequence of values, we can fold the operator over the sequence to obtain a single accumulated value. For example, because addition of integers is associative, addition can be folded over the sequence:
1, 2, 3, 4, 5, 6, 7, 8
from the left:
((((((1 + 2) + 3) + 4) + 5) + 6) + 7) + 8
or the right:
1 + (2 + (3 + (4 + (5 + (6 + (7 + 8))))))
or from the middle outward, by recursive/parallel splitting:
((1 + 2) + (3 + 4)) + ((5 + 6) + (7 + 8))
A 2-D view shows even more clearly the opportunity to evaluate sub-expressions in parallel. Assuming that addition is a constant-time operation, the left fold:
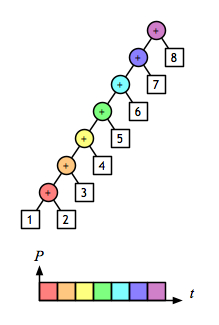
and the right fold:
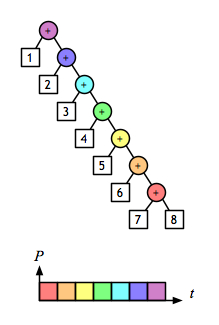
require linear time, but the balanced tree:
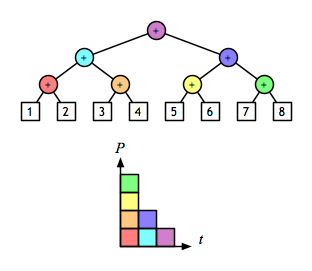
can be done in logarithmic time.
But the associative operation for the word-splitting task involves accumulating lists of words. With a naive implementation of linked lists, appending is not a constant-time operation; it is linear on the length of the left operand. So for this operation the right fold is linear on the size of the task:
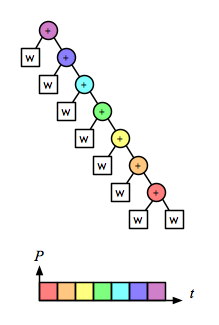
the left fold is quadratic:
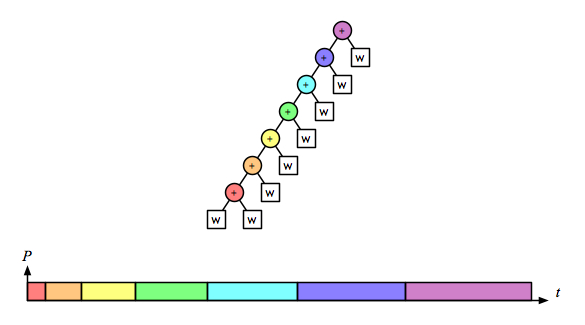
and the recursive/parallel version is linear:
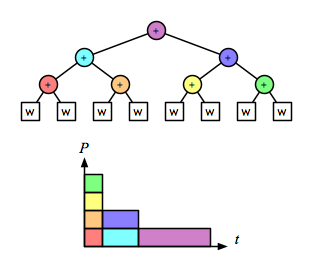
Comparing just the “parallel-activity-versus-time†parts of those diagrams makes it clear that right fold is as fast as the parallel version, and also does less total work:
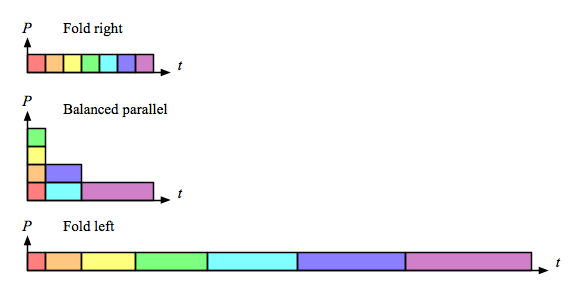
Of course, there are other ways to implement the sequence-of-words concept, and that is the whole point. This little example provides a nice illustration of how parallel execution of the wrong implementation is not a win.
Source : http://joelneely.wordpress.com/2011/03/05/why-data-structures-matter/

